Linux
- Bash
- Einzeiler
- Hacks und Commands
- Konfiguration
- ffmpeg
- Old commands and their replacements
- wttr.in
- Rechte im Dateisystem mehr als nur r,w,x
- SSH-Tunnel
- Howtos
- How to Create Local Debian Repository
- OpenMediaVault - Komplettanleitung zur Installation und Konfiguration
- Alpine IGEL-HW
- Linux audio recording guide (PulseAudio or PipeWire)
- How to Install NVIDIA Drivers on Debian
- 20 häufige Linux IPTables Firewall Regeln
- Paperless - Readme
- Debian Multimedia Repo
- Linux Page Cache
- Rechte im Dateisystem mehr als nur r,w,x
- Upgrade Debian Bookworm zu Trixie
- Thinclient
Bash
Commands, Scripte etc.
Einzeiler
grep -RnisI *
rename 'y/A-Z/a-z/' *
for i in ?.ogg; do mv $i 0$i; done
convert single digit to double digits
from 1.ogg 01.ogg
mount /path/to/file.iso /mnt/cdrom -oloop
DISPLAY=:0.0 import -window root /tmp/shot.png
mount |column -t sshfs name@server:/path/to/folder /path/to/mount/point mount -t tmpfs tmpfs /mnt -o size=1024m -Ausgabe, mount sshfs, RAM-Disk
python3 -m SimpleHTTPServer
net rpc shutdown -I ipAddressOfWindowsPC -U username%password
ping -i 60 -a IP_address (keep alive)
Uhrzeit einblenden:
while sleep 1;do tput sc;tput cup 0 $(($(tput cols)-29));date;tput rc;done &
Fortschrittsbalken:
echo "You can simulate on-screen typing just like in the movies" | pv -qL 10 tar cf - /home/ | pv | gzip > home.tar.gz
Netzverbindungen
lsof -i lsof -P -i -n
echo "!!" > foo.sh Create a script of the last executed command Sometimes commands are long, but useful, so it's helpful to be able to make them permanent without having to retype them. An alternative could use the history command, and a cut/sed line that works on your platform.
ifconfig | convert label:@- ip.png save command output to image
sudo touch /forcefsck dd if=/dev/mem | cat | strings
"Matrix"
ls -R | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'
man -t manpage | ps2pdf - filename.pdf
ffmpeg -f x11grab -r 25 -s 800x600 -i :0.0 /tmp/outputFile.mpg
Generate a random password 30 characters long
strings /dev/urandom | grep -o '[[:alnum:]]' | head -n 30 | tr -d '\n'; echo
Mysql-Live
watch -n 1 mysqladmin --user= --password= processlist
watch -t -n1 "date +%T|figlet"
du -s * | sort -n | tail
Busdurchsatz
dd if=/dev/zero of=/dev/null bs=1M count=32768
Fakework
cat /dev/urandom | hexdump -C | grep "ca fe"
for i in {0..600}; do echo $i; sleep 1; done | dialog --gauge "Install..." 6 40
export GREP_COLOR='1;32'; cat /dev/urandom | hexdump -C | grep --color=auto "ca fe"
j=0;while true; do let j=$j+1; for i in $(seq 0 20 100); do echo $i;sleep 1; done | dialog --gauge "Install part $j : sed $(perl -e "print int rand(99999)")"q;d" /usr/share/dict/words" 6 40;done
set Permissions
find ./ -type f -exec chmod 644 {} \; find ./ -type d -exec chmod 755 {} \;
grep ^Dirty /proc/meminfo
print ip connected
sudo tcpdump -i wlan0 -n ip | awk '{ print gensub(/(.)../,"\1","g",$3), $4, gensub(/(.)../,"\1","g",$5) }' | awk -F " > " '{print $1"\n"$2}'
ahttp://www.commandlinefu.com/commands/browse/sort-by-votes/25/50
grep -RnisI <pattern> *
------------
rename 'y/A-Z/a-z/' *
for i in ?.ogg; do mv $i 0$i; done
convert single digit to double digits
from 1.ogg 01.ogg
------------
mount /path/to/file.iso /mnt/cdrom -oloop
DISPLAY=:0.0 import -window root /tmp/shot.png
mount |column -t
sshfs name@server:/path/to/folder /path/to/mount/point
mount -t tmpfs tmpfs /mnt -o size=1024m
-Ausgabe, mount sshfs, RAM-Disk
------------
python3 -m SimpleHTTPServer
net rpc shutdown -I ipAddressOfWindowsPC -U username%password
ping -i 60 -a IP_address (keep alive)
#### Uhrzeit einblenden:
while sleep 1;do tput sc;tput cup 0 $(($(tput cols)-29));date;tput rc;done &
#### Fortschrittsbalken:
echo "You can simulate on-screen typing just like in the movies" | pv -qL 10
tar cf - /home/ | pv | gzip > home.tar.gz
#### Netzverbindungen
lsof -i
lsof -P -i -n
------------
echo "!!" > foo.sh
Create a script of the last executed command
Sometimes commands are long, but useful, so it's helpful to be able to make them permanent without having to retype them. An alternative could use the history command, and a cut/sed line that works on your platform.
------------
ifconfig | convert label:@- ip.png
save command output to image
sudo touch /forcefsck
dd if=/dev/mem | cat | strings
------------
##### "Matrix"
ls -R | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'
man -t manpage | ps2pdf - filename.pdf
ffmpeg -f x11grab -r 25 -s 800x600 -i :0.0 /tmp/outputFile.mpg
------------
##### Generate a random password 30 characters long
strings /dev/urandom | grep -o '[[:alnum:]]' | head -n 30 | tr -d '\n'; echo
------------
##### Mysql-Live
watch -n 1 mysqladmin --user=<user> --password=<password> processlist
watch -t -n1 "date +%T|figlet"
du -s * | sort -n | tail
------------
##### Busdurchsatz
dd if=/dev/zero of=/dev/null bs=1M count=32768
##### Fakework
cat /dev/urandom | hexdump -C | grep "ca fe"
for i in {0..600}; do echo $i; sleep 1; done | dialog --gauge "Install..." 6 40
export GREP_COLOR='1;32'; cat /dev/urandom | hexdump -C | grep --color=auto "ca fe"
j=0;while true; do let j=$j+1; for i in $(seq 0 20 100); do echo $i;sleep 1; done | dialog --gauge "Install part $j : `sed $(perl -e "print int rand(99999)")"q;d" /usr/share/dict/words`" 6 40;done
##### set Permissions
find ./ -type f -exec chmod 644 {} \;
find ./ -type d -exec chmod 755 {} \;
grep ^Dirty /proc/meminfo
##### print ip connected
sudo tcpdump -i wlan0 -n ip | awk '{ print gensub(/(.*)\..*/,"\\1","g",$3), $4, gensub(/(.*)\..*/,"\\1","g",$5) }' | awk -F " > " '{print $1"\n"$2}'
Hacks und Commands
**Images mit dd:**
Komprimiertes Image Vom Laufwerk erstellen:
dd if=/dev/sda | gzip --best >kodi-Image.gz
Zurückschreiben:
gunzip -c kodi-Image.gz | dd of=/dev/sda
**Dateiliste erstellen und die Liste mit einem Befehl abarbeiten:
**
*#/bin/bash
find /media/usbhd/Multimedia/Video/recordings/ -name "*.mpeg">liste
for f in $(cat liste) ; do
rm $f
done
***Encodieren nach Liste***
*#/bin/bash
find /Media/Video/recordings/ -mtime 90 -name "*.mpeg">mpeg_liste
for mpeg in $(cat mpeg_liste) ; do
mencoder -ovc x264 -oac mp3lame -ofps 25 -o $mpeg.mp4 $mpeg
done
--------------------------------------------------------------------
Find and do something...serial
find -iname '*.pdf' -exec cp {} /home/willi/pdf/ \;
-----------------------------------------------------------------------
**Audio extraieren aus *.mp4**
ffmpeg -i "The Eagles - Hotel California.mp4" -vn -acodec flac file.flac
**JPG aus *mp4 extraieren**
ffmpeg -i "vlc-record.mp4" -an -f image2 "output_%05d.jpg"
**mp4 aus jpg + Text einfügen
Insert Text in Video:
ffmpeg -i output_Montag2.mp4 -vf drawtext="fontfile=/usr/share/fonts/truetype/ttf-dejavu/DejaVuSerif.ttf:text='12.04.21':fontsize=20:fontcolor=blue:x=1800:y=10" with_text3.mp4
ffmpeg -framerate 25 -start_number 4 -i Photo/Montag/image-%04d.jpg -c:v libx264 -profile:v high -crf 20 -pix_fmt yuv420p /home/willi/Montag_16-20output.mp4
ffmpeg -framerate 25 -i install/MO/image%04d.jpg -c:v libx264 -profile:v high -crf 20 -pix_fmt yuv420p /home/willi/Montag_19output.mp4
------------
**Video kodieren x265**
ffmpeg -i "Der Auftragskiller - Zimmer 164.mp4" -c:v libx265 -preset medium -x265-params crf=25 -c:a aac -strict experimental -b:a 128k output.mp4
------------
**HD-Streams bearbeiten**
1. ffmpeg -i 'vlc-record-.ts' -vcodec copy -acodec copy 'Wallander.ts'
-korrigiert Fehler im Stream
2. ffmpeg -ss 00:05:55 -i 'Wallander.ts' -vcodec copy -acodec copy -bsf:a aac_adtstoasc -f mp4 'Wallander.mp4'
- ss: schneidet die ersten 34 Sekunden ab
- t : Schnitt an Streamposition 1:35:44 (gemessen ab -ss)
- bsf: behebt Fehler in der Audiospur
------------
Permissions von Files numerisch anzeigen:
stat -c "%A %a %N" *-----------------
**Leerzeichen in Dateinamen entfernen**
*#/bin/bash
for i in *\ *
do mv "$i" "${i// /_}"
done*
oder:
*#/bin/bash
for i in /media/usbhd/Multimedia/Video/recordings/Deutsches_Europa_Kino/*.mp4
do mv "$i" "${i// /_}"
done
------------
**Installation nach Paketliste**
#/bin/bash
for pkg in $(cat installed_packages.list) ; do
apt-get -y install $pkg
done
#Paketliste erstellt mit: dpkg -l|grep ii|awk '{print$2}'>installed_packages.list
------------
**Verschlüsseln/entschlüsseln mit ssl**
*
*#!/bin/bash*
*# make sure we get a file name*
if [ $# -lt 1 ]; then
echo "Usage: $0 filename"
exit 1
fi
openssl enc -e -aes256 -in "$1" -out "$1".enc*
*#!/bin/bash*
*# make sure we get 2 files*
if [ $# -lt 2 ]; then
echo "Usage: $0 encrypted_file decrypted_file"
exit 1
fi
openssl enc -d -aes256 -in "$1" -out "$2"
------------
**Streaming mit vlc**
**
**#/bin/bash
cvlc .mplayer/Sender.conf --extraintf http --sout udp:172.16.1.164&
exit
------------
#### Phpmyadmin für weiteren Server einrichten:
**Datei: /etc/phpmyadmin/config.inc.php**:
<?php
$cfg['blowfish_secret']='multiServerExample70518';
//any string of your choice (max. 46 characters)
$i = 0;
$i++; // server 1 :
$cfg['Servers'][$i]['auth_type'] = 'cookie'; // needed for pma 2.x
$cfg['Servers'][$i]['verbose'] = 'no1';
$cfg['Servers'][$i]['host'] = 'localhost';
$cfg['Servers'][$i]['extension'] = 'mysqli';
// more options for #1 ...
$i++; // server 2 :
$cfg['Servers'][$i]['auth_type'] = 'cookie';
$cfg['Servers'][$i]['verbose'] = 'no2';
$cfg['Servers'][$i]['host'] = 'banapi';//or ip:'10.9.8.1'
// this server must allow remote clients, e.g., host 10.9.8.%
// not only in mysql.host but also in the startup configuration
$cfg['Servers'][$i]['extension'] = 'mysqli';
// more options for #2 ...
// end of server sections
$cfg['ServerDefault'] = 0; // to choose the server on startup
// further general options ...
?>
------------
#### Teamviewer auf 64bit
Vielleicht zur Erklärung:
Das 64-Bit-Paket verwendet zum installieren das Paket Debiania32-libs, welches seit Wheezy nicht mehr vorhanden ist.
Du musst also die 32Bit Version installieren und vorher Multiarch freischalten mit:
dpkg --add-architecture i386
Danach ein
apt-get update
Jetzt das Paket herunterladen:
wget http://download.teamviewer.com/download/teamviewer_i386.deb
Das Paket installieren:
dpkg -i teamviewer_i386.deb
Und fehlende Abhängigkeiten installieren:
apt-get install -f
Steht auch sonst alles hier:
-> http://www.teamviewer.com/en/help/363-How-do-I-install-TeamViewer-on-my-Linux-distribution.aspx
------------
#### Samba meckert uber Cups -das gar nicht installiert ist...
#####prevent logsentries about cups####
load printers = no
printing = bsd
printcap name = /dev/null
disable spoolss = yes
------------
#### NATNAT: Dem Kernel das Weiterleiten beibringen
Wir möchten also dem Kernel das folgende mitteilen: Bei Paketen aus dem lokalen Netz, dessen IP-Adresse
nicht mit seiner übereinstimmt, soll er die Absender-Adresse auf sich selbst ändern. Dazu machen wir noch
die Annahme, dass das erste Netzwerk-Interface des Linux-Routers "eth0" mit dem lokalen Netz verbunden ist
und die Internet-Verbindung am zweiten Interface "eth1" verfügbar ist.
Der Befehl zur Freigabe der Internet-Verbindung lautet dann:
*Anbinden eines LAN an das Internet*
$> iptables -t nat -A POSTROUTING -o tun0 -j MASQUERADE
iptables-Tabellen speichern
**Beispiel um iptables-Tabellen zu speichern**:
sudo iptables-save > /etc/iptables_01.save
**Beispiel um iptables-Tabellen wieder zu laden. Vorhandenen Regeln werden dabei gelöscht bzw. überschrieben.**
sudo iptables-restore < /etc/iptables_01.save
**So werden bereits vorhandene Regeln nicht gelöscht:**
sudo iptables-restore -n < /etc/iptables_01.save
sudo iptables-restore --noflush < /etc/iptables_01.save
So können natürlich auch mehrere Tabellen gespeichert und je nach Bedarf wieder geladen werden.
**iptables-Tabellen löschen**
sudo iptables --flush
#### [Linux Nat Toutorial](http://www.karlrupp.net/de/computer/nat_tutorial "Linux Nat Toutorial")
------------
#### Mit sed alle Zeilen löschen, die "pattern" enthalten
sed '/pattern to match/d' ./infile
To directly modify the file (and create a backup):
sed -i.bak '/pattern to match/d' ./infile
#/bin/bash
mount -t cifs //fritz.box/fritz.nas /home/willi/smb -o username=Maria,password=oma
**SSH Passwordless Login**
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub user@remote-system
** Dateiberechtigungen sichern**
To back up permissions in the current directory and its subdirectories recursively:
getfacl -R >permissions.facl
To restore permissions:
setfacl --restore=permissions.facl
**Filesystemcheck:**
umount /media/veracrypt1
fsck /dev/mapper/veracrypt1
**Splitten von MP3:**
mp3splt:
Automatisch:
mp3splt -c query file.mp3
Manuell
mp3splt -s -p min=2 file.mp3
**Mount Winfreigabe:**
mount -t cifs //fritz.box/fritz.nas /home/willi/smb -o username=Maria,password=oma
wget komplette Seite
wget -r -l 0 -p -k -D alan-g.me.uk -L -np http://www.alan-g.me.uk/l2p/
PiHole Docker Unbound – Error starting userland proxy: listen tcp4 0.0.0.0:53: bind: address already in use
systemctl disable systemd-resolved.service systemctl stop systemd-resolved.service rm /etc/resolv.conf echo 1.1.1.1 > /etc/resolv.conf
----------------------------------------------------------------------------------------------
Symbolic links
ln -s {source-filename} {symbolic-filename}
---------------------------------------------------------------------------------------------------------------------------------------------
Performance VPS-Server
apt update
apt upgrade -y
apt install sysbench fio bpytop iperf3
lscpu
lspci
ping ipv4.ipv64.net
ping ipv6.ipv64.net
iperf3 -c speedtest.myloc.de -p 5200 -P 10 -4
iperf3 -c speedtest.myloc.de -p 5200 -P 10 -4 -R
sysbench cpu run
sysbench memory run
dd if=/dev/zero of=/root/test.iso bs=128k count=10000
## Schreib- / Lesetests
fio --name=write-test --size=1G --filename=/tmp/fio-testfile --bs=128k --rw=write --direct=1 --numjobs=1 --time_based --runtime=30 --group_reporting
fio --name=read-test --size=1G --filename=/tmp/fio-testfile --bs=128k --rw=read --direct=1 --numjobs=1 --time_based --runtime=30 --group_reporting
fio --name=realistic-test --filename=/tmp/fio-testfile --size=2G --bs=64k --rw=randrw --rwmixread=70 --direct=1 --iodepth=16 --numjobs=4 --time_based --runtime=60 --group_reportingKonfiguration
Größe von /var/log/journal begrenzen
Über die Zeit wächst das Verzeichnis /var/log/journal deutlich an. Gerade auf kleinen vServern ist das unangenehm. Dies kann schnell auf mehrere Gigabyte anwachsen. Dies kann man in der Datei /etc/systemd/journald.conf begrenzen:
[Journal]
SystemMaxUse=32M
Einmalig kann dies auch mit folgenden Befehl aufgeräumt werden.
journalctl --vacuum-size=32MAdd User to sudoers:
usermod -aG sudo usernameAutomatische Updates:
Alternativ ist im Anacron bereits ein entsprechender Mechanismus implementiert: /etc/cron.daily/apt .
Nach Erstellen der Datei /etc/apt/apt.conf.d/02periodic sollte eine tägliche Systemaktualisierung starten. Hier der Inhalt der Datei 02periodic:
APT::Periodic::Enable "1"; APT::Periodic::Update-Package-Lists "1"; APT::Periodic::Download-Upgradeable-Packages "1"; APT::Periodic::AutocleanInterval "7"; APT::Periodic::Unattended-Upgrade "1"; APT::Periodic::Verbose "2"; APT::Periodic::RandomSleep "11";
Owncloud-Client ist nicht in den Repos:
wget -nv https://download.owncloud.com/desktop/ownCloud/stable/latest/linux/Debian_11/Release.key -O - | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/owncloud.gpg > /dev/null
echo 'deb https://download.owncloud.com/desktop/ownCloud/stable/latest/linux/Debian_11/ /' | sudo tee -a /etc/apt/sources.list.d/owncloud.list
apt-get update -y
___________________________________________________________________________________________________________________________
Teamviewer Debian 12
apt-get update
apt install curl apt-transport-https
curl -fSsL https://download.teamviewer.com/download/linux/signature/TeamViewer2017.asc | sudo gpg --dearmor | sudo tee /usr/share/keyrings/teamview.gpg > /dev/null
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/teamview.gpg] http://linux.teamviewer.com/deb stable main" | sudo tee /etc/apt/sources.list.d/teamviewer.list
apt-get update
Armbian - WIFI
use NMCLI
$ nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet connected Wired connection 1 wlp2s0 wifi disconnected -- lo loopback unmanaged --
to check radio
$ nmcli radio WIFI-HW WIFI WWAN-HW WWAN enabled enabled enabled enabled
Let's see what's out there... scan for AP's
$ nmcli dev wifi list SSID MODE CHAN RATE SIGNAL BARS SECURITY MYSSID Infra 11 54 Mbit/s 100 ▂▄▆█ WPA2 MYSSID Infra 132 54 Mbit/s 100 ▂▄▆█ WPA2 SOMEOTHERSSID Infra 52 54 Mbit/s 49 ▂▄__ WPA2 MYSSID Infra 149 54 Mbit/s 45 ▂▄__ WPA2 MYSSID Infra 11 54 Mbit/s 42 ▂▄__ WPA2 SOMEOTHERSSID Infra 1 54 Mbit/s 27 ▂___ WPA2
Now, let's connect to WiFi (note, one must be root or sudo access)
Connecting to an open AP
$ nmcli device wifi connect <SSID|BSSID>
For a password protected AP, see below
$ nmcli device wifi connect <SSID|BSSID> password <password>
To set up a device as an AP - this assumes that WLAN0 is the wireless interface...
$ nmcli dev wifi hotspot ifname wlan0 <SSID> password "<password>"
---------------------------------------------------------------------------------------------------------
Mutimedia Repository einbinden
- Add the following line to /etc/apt/sources.list:
deb http://www.deb-multimedia.org trixie main - Update the package index:
$ sudo apt-get update -oAcquire::AllowInsecureRepositories=true - Install GPG key of the repository:
$ sudo apt-get install deb-multimedia-keyring - Install deb-multimedia-keyring deb package:
$ sudo apt-get install deb-multimedia-keyring
ffmpeg
- How to split video into 30 seconds chunks. This example creates 3 segments from the beginning of video starting at time 0 seconds of original video. i.e. <30s><30s><30s><... long big chunk>.
Code:ffmpeg -ss 00:00:30 -vsync 0 -t 00:00:30 -i webcam_2012-03-18_00_33_58.mp4 -vcodec copy -acodec copy sub_video1.mp4 ffmpeg -ss 00:01:00 -vsync 0 -t 00:00:30 -i webcam_2012-03-18_00_33_58.mp4 -vcodec copy -acodec copy sub_video2.mp4 ffmpeg -ss 00:01:30 -vsync 0 -t 00:00:30 -i webcam_2012-03-18_00_33_58.mp4 -vcodec copy -acodec copy sub_video3.mp4
- How to split video into 30 seconds chunks. This example creates 3 segments from the beginning of video starting at time 0 seconds of original video. i.e. <30s><30s><30s><... long big chunk>.
- How to extract a still JPEG image from a video at the 20 second spot.
Code:ffmpeg -i webcam_2012-03-18_00_33_58.mp4 -r 0.1 -t 20 image%3d.jpg
- How to extract a still JPEG image from a video at the 20 second spot.
- Here are some other examples to save you time:
19-FFmpeg commands for all needs - Good articles and examples here:
FFMpeg – The swiss army knife of Internet streaming – part I
FFMpeg – The swiss army knife of Internet streaming – part II
FFMpeg – The swiss army knife of Internet streaming – part III
FFMpeg – The swiss army knife of Internet streaming – part IV - Screencasting: How to capture your desktop screen and audio.
Nice examples here. - How to overlay text on the video at a specific window position.
Code:ffmpeg -i sub_video3.mp4 -vf \ drawtext="fontfile=/usr/share/fonts/truetype/ttf-dejavu/DejaVuSerif.ttf: \
text='Text to write is this one, overlaid':fontsize=20:fontcolor=red:x=100:y=100" \ with_text3.mp4
- Here are some other examples to save you time:
- How to grab audio from your desktop/laptop microphone.
Code:ffmpeg -f alsa -ac 2 -i pulse mic_test.mp3
- How to grab audio from your desktop/laptop microphone.
- Two examples that overlays text over video which timestamps the output video to start at the specified time (timecode).
Code:#Begin at 1:00 ffmpeg -y -i in_video.mp4 \ -vf "drawtext=fontcolor=white: fontsize=16: \ fontfile=/usr/share/fonts/truetype/ttf-dejavu/DejaVuSans.ttf: \ box=1:boxcolor=black@0.3:x=50:y=20: \ timecode='00\\:01\\:00\\;02':rate=30000/1001" \ out.mp4 #Begin at 3:59, with a specified codec ffmpeg -i in_video.mp4 \ -vf "drawtext=fontfile=/usr/share/fonts/truetype/ttf-dejavu/DejaVuSans.ttf: \ x=10: y=20: fontsize=32: boxcolor=black@0.5:box=1: \ rate=30000/1001:timecode='00\\:03\\:59\\;27'" \ -r 30000/1001 \ -vcodec mpeg4 \ nostra_timecode.mp4
- Two examples that overlays text over video which timestamps the output video to start at the specified time (timecode).
- A example that overlays text over video which shows updating timestamps on the output video.
Code:ffmpeg -i video.mp4 -vf drawtext="fontfile=/usr/share/fonts/truetype/ttf-dejavu/DejaVuSans.ttf: \
text='%T %D': x=10: y=10: fontsize=24: fontcolor=black" \
-vcodec libx264 -preset fast -crf 34 -threads 0 \
strftime.mp4
- A example that overlays text over video which shows updating timestamps on the output video.
- A example that overlays text over an mjpeg input stream generated with mjpeg_streamer from a usb webcam.
Code:ffmpeg -fflags +genpts -t 600 -f mjpeg -r 8 -s 640x480 \ -i http://localhost:8080/?action=stream -vcodec mpeg4 \ -vf drawtext="fontfile=/usr/share/fonts/TTF/mitra.ttf:x=70:y=455: \ text='\%H\:\%M\:\%S | \%a \%d/\%b/\%Y | S500ATV | camera 0': \ fontcolor=0xFFFFFFFF:fontsize=18: \ shadowcolor=0x000000EE:shadowx=1:shadowy=1" \ -b 1500000 -r 8 \ video_file.avi
- A example that overlays text over an mjpeg input stream generated with mjpeg_streamer from a usb webcam.
- If you want to add subtitles to a video file (in_video.avi) with audio to a new output video with subtitles. Note that since video had audio we are not passing the audio file we just map audio to the 2nd (0:1) component of the output. Input had 2 components, 0 and 1. Output has three (3) components, 0, 1, and 2. So, we are mapping the 1st input component to the 1st and 2nd output components (0:0) and (0:1). We also map the 2nd input component to the 3rd out put component (1:2).
Code:ffmpeg -i in_video.avi -c:v libx264 -vpre ipod640 -s 480x240 -b 256k -map 0:0 \ -c:a libfaac -ar 48000 -ab 128k -ac 2 -map 0:1 \ -i in_subtitles.srt -c:s copy -map 1:2 out_video_with_titles.m4v #That is, follow this type of command format: ffmpeg -i Input_1.avi -c:v copy -map 0:0 \ -i Input_2.wav -c:a copy -map 1:1 \ -i Input_3.srt -c:s copy -map 2:2 Output.mp4
- If you want to add subtitles to a video file (in_video.avi) with audio to a new output video with subtitles. Note that since video had audio we are not passing the audio file we just map audio to the 2nd (0:1) component of the output. Input had 2 components, 0 and 1. Output has three (3) components, 0, 1, and 2. So, we are mapping the 1st input component to the 1st and 2nd output components (0:0) and (0:1). We also map the 2nd input component to the 3rd out put component (1:2).
- ffmpeg: the mother of all command-lines
Nice complex command explained!
Re: HOWTO: Proper Screencasting on Linux
Note: This was the original post not done by me, but i will try to update if anything new comes up
While many screencasting tools exist on Linux, none of them is able to really pull a high-quality screencast. I’ve tried almost all existing tools such as recordmydesktop, xvidcap, istanbul, wink etc.. and all of them produced poor results. Horrible video/audio quality, bad sync, lots of limitations, and some even simply segfault while doing the recording. The real solution and the ultimate answer to all your screencasting needs on Linux has been there for quite a long time. It is called FFmpeg. I am surprised to see that many people would just overlook this awesome piece of software.Demo Video http://www.youtube.com/watch?v=Ewxm6T6rXP0
What is FFmpeg?
From the official website:
Quote:
In this tutorial, I’ll suppose you’re using Ubuntu Linux Karmic or Lucid, but the tutorial should also work for other versions with slight modifications.FFmpeg is a complete, cross-platform solution to record, convert and stream audio and video. It includes libavcodec – the leading audio/video codec library.
Preparation:
For this tutorial, you’ll need FFmpeg (preferably a recent revision) compiled with "--enable-x11grab" and the following libraries:
* libx264
* libfaac
* libvpx
* libvorbis
* libxvid
* libmp3lame
* libtheora
Because the version of FFmpeg that is available in the repositories is not compiled with these libraries, you need to compile it yourself. There is an easy-to-follow guide for compiling FFmpeg on ubuntu with those libraries here:
At this point, you should have the latest FFmpeg built with the needed encoding libraries. Let’s go to our main subject:
Screencasting:
We will do screencasting in 2 steps:
* Capture a lossless, crystal-clear video stream with lossless audio.
* Encode the resulting lossless file to a compressed version suitable for internet use.
The reason we’re doing it in a 2-step scheme (instead of just encoding directly as we capture) is that compressing a video with good quality takes some time and processing power that isn’t possible on the fly. The idea is to use the first step to only capture lossless audio/video feeds as fast as possible and store them, then use the 2nd step to do the real compression and get a better result. The 2nd step is needed because the losslessly-captured file is tremendously large to be used on the web.
Step 1:
Just for the record, basic ffmpeg syntax is:
Code:
Learn by example, fire up your terminal application and enter the following command:ffmpeg [input options] -i [input file] [output options] [output file]
Code:
ffmpeg -f alsa -ac 2 -i pulse -f x11grab -r 30 -s 1024x768 -i :0.0 -acodec pcm_s16le -vcodec libx264 -preset ultrafast -crf 0 -threads 0 output.mkv
Then press Enter to start the capturing process. To stop recording, go back to the terminal and press q.
In the above command, we capture audio from pulse (pulseaudio sound server) and encode it to lossless raw PCM with 2 audio channels (stereo). Then, we grab a video stream from x11 at a frame rate of 30 and a size of 1024×768 from the display :0.0 and encode it to lossless h264 using libx264. Using -threads 0 means automatic thread detection. If your distribution does not use the pulseaudio sound system, see FAQ section. The resulting streams will be muxed in a Matroska container (.mkv). The output file “output.mkv” will be saved to the current working directory.
Before we move to step 2, let’s look at things you can change in step 1. Obviously, the most important of which is the resolution. If you want to capture your entire desktop, then you have to enter the screen resolution you’re working at. It is also possible to capture a specific area of the screen by specifying a capture size that is smaller than the resolution. You can optionally offset this area by adding +X,Y after :0.0 which means it will look something like this:
Code:
This tells it to capture a rectangle of 800×600 with an X offset of 200 pixels and a Y offset of 100 pixels (the offset starting point is the top-left corner of the screen). Note that if you offset the capture area out of the screen, it will give you an error.-s 800x600 -i :0.0+200,100
Another thing you can change is the video frame rate (FPS). In the example above we used -r 30 which means capture at 30 FPS. You can change this value to whatever frame rate you want.
Step 2:
Now that we have the lossless file, let’s encode it to suit our needs. From here on, it all depends on what you’re planning to do with your screencast, but we’ll provide some basic examples and from there you move on.
Example 1:
Code:
In the above example, we encode the audio to AAC at a bitrate of 128k with 2 audio channels (stereo). We encode the video to the high quality H.264 video compression standard. We use the preset "slow" and a CRF value of 22 for rate control. The output file will be named “our-final-product.mp4″ and will be muxed in an .mp4 container. Note that FFmpeg determines the container format of the output file based on the extension you specify (i.e. if you specify the extension as .mkv, your file will be muxed into an .mkv matroska container). You can tweak the CRF value to get different results. The lower you set the CRF value, the better your video’s quality will be, and consequently the file size and encoding time will increase, and vice-versa.ffmpeg -i output.mkv -acodec libfaac -ab 128k -ac 2 -vcodec libx264 -preset slow -crf 22 -threads 0 our-final-product.mp4
Example 2:
WebM is a new, high-quality, free/open format that can be played in modern web browsers that support the HTML5 <video> tag. Since libvpx does not have a constant quality mode yet, we're doing the encode in 2 passes:
Pass 1:
Code:
Pass 2:ffmpeg -i output.mkv -an -vcodec libvpx -b 1000k -pass 1 our-final-product.webm
Code:
Change the bitrate (-b 1000k) to control the size/quality tradeoff. Also, change the number of threads (-threads 2) to suit the number of threads your CPU has. If your CPU is not multi-threaded, you can omit the -threads option completely. If you have a modern web browser, you can open the file and play it natively inside it. A WebM file consists of VP8 video and Vorbis audio mulitplexed into a .webm container (which is basically a subset of the Matroska container, aka .mkv).ffmpeg -i output.mkv -acodec libvorbis -ab 128k -ac 2 -vcodec libvpx -b 1000k -threads 2 -pass 2 our-final-product.webm
Example 3:
Code:
Usually when you start screencasting, there will be a few moments of “getting ready” that you may want to cut out of your final product. Same thing near the end. It is possible to only encode a specific range of the original lossless file you captured using the -ss and -t options. These options can come before the input file option (i.e. before -i output.mkv) or after it. If they are specified after it, seeking will be more accurate but a lot slower. In the above example, we specified the starting point of the encoding of our final product after 10 seconds from the start of the original input file using -ss 00:00:10. We also specify the duration of the encoding to be 7 minutes and 22 seconds, because we want to effectively cut something at the end we don’t want to show. If there isn’t anything you want to hide at the end, you can just omit the -t option altogether. We use Vorbis and H.264 for the audio and video respectively and mux the entire thing to an .mkv container. This mix of Vorbis/H.264/Matroska is my favorite .ffmpeg -ss 00:00:10 -t 00:07:22 -i output.mkv -acodec libvorbis -ab 128k -ac 2 -vcodec libx264 -preset slow -crf 22 -threads 0 our-final-product.mkv
Example 4:
Code:
Here we have a typical avi with xvid and mp3. The options from “-me_method full” to “-trellis 1″ are encoding parameters for libxvid. You can see that we used libmp3lame to encode the audio with the same options we used for the other examples. For video, tweaking the value of -qscale will give different results. Smaller value means higher video quality but increased file size and encoding time (Similar to libx264’s -crf in the first example) . The output file is muxed into an .avi container.ffmpeg -i output.mkv -acodec libmp3lame -ab 128k -ac 2 -vcodec libxvid -qscale 8 -me_method full -mbd rd -flags +gmc+qpel+mv4 -trellis 1 -threads 0 our-final-product.avi
Example 5:
Code:
In the above example, we have a completely free file , with vorbis for audio and theora for video. The video is encoded at 1000k bitrate and the output file is muxed to an .ogg container. The audio quality should be great since vorbis is a great audio codec, but the video quality will not be as good. Theora lags behind in almost every aspect of video compression. See the WebM example above (example 2) for a better free and open alternative.ffmpeg -i output.mkv -acodec libvorbis -ab 128k -ac 2 -vcodec libtheora -b 1000k our-final-product.ogg
There are many tricks you can use with step 2. You can record your entire desktop at step 1 and then crop it in step 2 to only cover the area you worked on. You can also resize your screencast in step 2. Dealing with these situations and many others is beyond the scope of this tutorial.
FAQ:
Q: How do I get the exact size and coordinates of a specific window I want to capture?
A: Use a command called “xwininfo“. Basically, you run this command and then click on the window that you want to capture. It will then print the window information to the terminal. This command prints a lot of information, but what you need are the following lines:
Absolute upper-left X:
Absolute upper-left Y:
Width:
Height:
If the command, for example, prints:
Absolute upper-left X: 383
Absolute upper-left Y: 184
Width: 665
Height: 486
Then, you will adapt it to FFmpeg like this:
-s 664x486 -i :0.0+383,184
Note that we used 664 instead of 665 for the width since ffmpeg only accepts resolutions divisible by 2.
You can use the following command line combination with "xwininfo" to only print the information you’ll be needing:
Code:
Q: How can I control PulseAudio input? (e.g. capture application audio instead of mic)xwininfo | grep -e Width -e Height -e Absolute
A: Install “pavucontrol“. Start recording with ffmpeg. Start pavucontrol. Go to the “Recording” tab and you’ll find ffmpeg listed there. Change audio capture from “Internal Audio Analog Stereo” to “Monitor of Internal Audio Analog Stereo“.
Now it should record system and application audio instead of microphone.
This setting will be remembered. The next time you want to capture with FFmpeg, it will automatically start recording system audio. If you want to revert this, use pavucontrol again to change back to microphone input.
Q: What are the recommended codecs/container to use if I’m planning to upload my screencast to YouTube?
A: YouTube recommends uploading clips using H.264 for the video and AAC for the audio in an .mp4 container (as in example 1 of step 2). This is the safest format to upload into because some codecs do have issues with YouTube. Refer to this page for other recommended codecs and containers for YouTube.
Q: What do I do if my system does not use the PulseAudio sound server?
A: Most recent Linux distributions have PulseAudio installed by default, but if your system does not have PulseAudio, then try replacing “-f alsa -ac 2 -i pulse” with something like:
-f alsa -ac 2 -i hw:0,0
Many users of this guide reported success with the above options. You might have to change the 0,0 to match that of your sound device. You could also try:
-f alsa -ac 2 -i /dev/dsp
Other users reported success with:
-f oss -ac 2 -i /dev/dsp
Basically there are many ways to do it, and it depends on your system’s sound configurations and hardware.
Q: How can I pause/resume screencasting?
A: That isn’t possible with ffmpeg yet, but you can use mkvmerge to achieve the same result. You can install this program from your distribution’s package management system under the package name mkvtoolnix, or download it from the official website. This program allows you to concatenate mkv files with identically-encoded streams to a single file. Meaning that if you want to make a pause from screencasting, you’ll just stop recording part 1, then start recording part 2 as another file, and finally concatenate (i.e. add) these 2 parts into a single screencast ready for final compression. You can do this for as many parts as you like. Example:
Code:
This command pruduces a video file named “complete.mkv” that has all the parts put together in the order they were specified into on the command line.mkvmerge -o complete.mkv part1.mkv +part2.mkv +part3.mkv +part4.mkv
However, note that all the parts you want to concatenate must have exactly the same size/framerate/encoding parameters, otherwise it won’t work. You can’t add files with different encoding options to each other.
Final note, before you start recording part 2 of your screencast, be sure to change the output file name, or else your previous precious work might be overwritten.
Q: I want to select an area of the screen with my mouse and get ffmpeg to record it. Is it possible?
A: Yes! There is a simple tool called "xrectsel" that you can use to select an area of the screen by drawing with your mouse, and it will print your selection coordinates which you can then use in ffmpeg. This tool comes as an auxiliary tool with the "FFcast2" bash script that wraps around ffmpeg's screencasting abilities
Q: How do I hide the mouse cursor?
A: Add "+nomouse" after ":0.0" to look like this:
Code:
(thanks again FakeOutdoorsman):0.0+nomouse
Q: I have a problem, error message, or ffmpeg doesn't work the way I expected it to do. How do I get help?
A: The best way to get help with ffmpeg is to login to the official IRC support channel for ffmpeg #ffmpeg @ irc.freenode.net, because 1) you will get an instant reply or engage in discussion about your problem and provide realtime feedback 2) the developers of ffmpeg know more about ffmpeg and its problems than we do (and they almost always hang around there and help people). If you want to ask for help here, you're most welcome. We'll try our best to support you, but bear in mind that the answer might come late, or we may not be able to help you with your problem.
Credits
verb3k
Dark_Shikari
FakeOutdoorsman
Updates:
Added FFcast2 reference link
changed syntax for new presets format on step1 (Thanks FakeOutdoorsman)
Removed all broken links, other junks
Old commands and their replacements

wttr.in
Benutzung:
$ curl wttr.in # aktuelle Position
$ curl wttr.in/muc # Wetter, Flughafen München
Unterstütze Ortstypen:
/paris # Stadtname
/~Eiffel+tower # wählbarer Ort
/Москва # Unicode Name von einem Ort in irgendeiner Sprache
/muc # IATA-Flughafencode (3 Buchstaben)
/@stackoverflow.com # Domainname
/94107 # Area code (nur für USA)
/-78.46,106.79 # GPS Koordinaten
Spezielle Orte:
/moon # Mondphase (bei Benutzung von z.B. ,+US oder ,+France wird die Phase des jeweiligen Ortes angezeigt)
/moon@2016-10-25 # Mondphase eines Tages (@2016-10-25)
Maßeinheiten:
?m # metrisch (SI) (standard überall außer bei Orten in den USA)
?u # USCS (standard in den USA)
?M # Windgeschwindigkeiten in m/s
Ansichteinstellungen:
?0 # Zeige nur aktuelles Wetter
?1 # Zeige aktuelles Wetter + 1 Tag
?2 # Zeige aktuelles Wetter + 2 Tage
?n # Kleine Version (nur Tag & Nacht)
?q # Schmale Version (kein 'Wetter Report' Text)
?Q # Superschmale Version (kein 'Wetter Report' Text und Ortsname)
?T # Keine Farben
PNG optionen:
/paris.png # generiert eine PNG Datei
?p # fügt einen Rahmen hinzu
?t # Transparenz von 150
transparency=... # Transparenz von 0 bis 255 (255 = nicht transparent)
Optionen können kombiniert werden:
/Paris?0pq
/Paris?0pq&lang=fr
/Paris_0pq.png # wird eine PNG benutzt, dann werden diese Optionen nach einem _ (Unterstrich) hinzugefügt
/Rome_0pq_lang=it.png # einzelne Optionen werden mit einem _ (Unterstrich) getrennt
Lokalisierung:
$ curl fr.wttr.in/Paris
$ curl wttr.in/paris?lang=fr
$ curl -H "Accept-Language: fr" wttr.in/paris
Unterstützte Sprachen:
am ar af be bn ca da de el et fr fa gl hi hu ia id it lt mg nb nl oc pl pt-br ro ru ta tr th uk vi zh-cn zh-tw (supported)
az bg bs cy cs eo es eu fi ga hi hr hy is ja jv ka kk ko ky lv mk ml mr nl fy nn pt pt-br sk sl sr sr-lat sv sw te uz zh zu he (in progress)
Spezialseiten:
/:help # zeigt diese Seite an
/:bash.function # zeigt empfehlenswerte bash Funktion wttr() an
/:translation # zeigt Informationen der Übersetzer an
Rechte im Dateisystem mehr als nur r,w,x
Erfahren Sie, wie Sie einfacher Verzeichnisstrukturen für Mitarbeiter bereitstellen und diese mit den benötigten Rechten und ACLs versehen können.
Stefan Kania 08. September 2015

Jeder der schon mal mit Linux auf der Kommandozeile gearbeitet hat und dort administrativ tätig war, kennt diese drei Buchstaben: "rwx" und das pro Eintrag im Dateisystem dreimal. Die Dateisystemberechtigungen! Aber was verbirgt sich noch hinter dem Begriff "Dateisystemberechtigungen"? Weit mehr als nur die drei Berechtigungen "read", "write" und "execute". Mit diesem Artikel werde ich weitere Facetten der Dateisystemberechtigungen wie "special Bits", "Access Control Lists" und "erweiterte Attribute" ansprechen.
Immer wieder höre ich in den Grundlagenseminaren zu Linux von Teilnehmern, dass man mit den drei einfachen Rechten "read", "write" und "execute" nicht viel anfangen kann. Dass komplexe Abbildungen von Zugriffsrechten unter Windows viel besser seien. Wo reicht es denn heute noch aus, dass man nur einem Benutzer und einer Gruppe Rechte an einem Verzeichnis oder einer Datei geben kann? Aber nicht nur Einsteiger, auch so mancher Admin stößt immer wieder an seine Grenzen.
Ich will in diesem Artikel nicht nur erklären, wie die Rechte funktionieren, was man mit den Rechten alles machen kann, sondern ich will auch praktische Tipps geben, die vielleicht das Leben mit den Dateisystemrechten etwas angenehmer machen können. Neben den bekannten Dateisystemrechten gehören auch noch die "special Bits", die "Access Contol Lists (ACL)" und die erweiterten Attribute in ein gut geplantes Berechtigungskonzept. Auch diese Themen werde ich in diesem Artikel ansprechen.
Die altbekannten Buchstaben "r","w","x"
Im Schnelldurchlauf will ich hier noch mal die Rechte "read", "write" und "execute" erklären, wobei ich dabei auch die unterschiedlichen Bedeutungen der Rechte an Dateien und Verzeichnissen erläutern werde:
- read
Das "read"-Recht an einer Datei bedeutet, die Datei kann zum Lesen geöffnet werden. Der Anwender der dieses Recht hat, kann den Inhalt lesen, aber nicht verändern. Das "read"-Recht an einem Verzeichnis erlaubt es, dass ein Anwender sich den Inhalt des Verzeichnisses mit "ls" anzeigen lassen kann. - write
Das "write"-Recht an einer Datei erlaubt es dem Anwender, den Inhalt einer Datei zu verändern. Er hat dadurch nicht das Recht, den Dateinamen zu ändern oder gar eine Datei zu löschen. Erst wenn ein Anwender das "write"-Recht an einem Verzeichnis hat, kann er die Einträge im Verzeichnis löschen, umbenennen und neue Einträge erstellen. Die Vergabe des "write"-Rechts an einem Verzeichnis sollte daher immer gut überlegt sein. Das Recht erlaubt es einem Anwender, alle Einträge in dem Verzeichnis zu löschen, auch wenn er an den Einträgen selbst keine Rechte hat. In allen heutigen Unix/Linux-Systemen muss der Anwender aber alle drei Rechte besitzen, um Einträge löschen, umbenennen oder erstellen zu können. - execute
Das "execute"-Recht erlaubt es einem Anwender, eine Datei auszuführen. Auf Binärdateien und Shell-Skripte muss immer das "execute"-Recht gesetzt sein, damit ein Anwender das Programm oder Shell-Skript ausführen kann. Hat ein Anwender das "execute"-Recht an einem Verzeichnis, kann er mit dem Kommando "cd" in das Verzeichnis wechseln.
user, group, other
Neben den Rechten selbst gibt es dann noch die Zuordnung der Rechte. Es gibt drei Berechtigungszuordnungen: Da wäre als erstes der Besitzer einer Datei (user), dann die besitzende Gruppe (group) und abschließend noch der Rest der Welt (other). Jeder dieser Berechtigungszuordnungen können die Rechte "read", "write" und "execute" zugeordnet werden. Ein Anwender kann aber immer nur die Rechte über eine der Berechtigungszuordnungen erhalten. Er ist also entweder der Besitzer einer Datei, dann erhält er die Rechte von "user", oder er ist Mitglied der besitzenden Gruppe, dann erhält er die Rechte von "group". Wenn er weder Besitzer noch Mitglied der besitzenden Gruppe ist, erhält er immer die Rechte von "other". Sie sehen schon, Rechte über "other" zu vergeben ist keine gute Lösung, da Sie den Zugriff auf Dateisystemeinträge nicht wirklich steuern können.
Immer alles Oktal
Systeme können nichts mit Buchstaben wie "r", "w" oder "x" anfangen, Systeme benötigen Zahlen und die am besten im Binärformat. Deshalb werden die Berechtigungen intern in Binärwerten mit drei Stellen abgebildet. Daraus entstehen dann die Oktalwerte für die Rechte wie Sie sie in der Tabelle sehen können. Egal ob für "user", "group" oder "other" – die Rechte haben dabei die folgenden Wertigkeiten:
Recht Binärwert Oktalwert -------- ------------ ---------------- read 2^2 4 write 2^1 2 execute 2^0 1
Werden also alle Rechte an eine Berechtigungszuordnung vergeben, ergibt das einen Oktalwert von "7". Maximal also "777".
Woher kommen die Rechte im Dateisystem?
Wenn Sie eine Datei oder ein Verzeichnis anlegen, haben diese Einträge bereits Berechtigungen, aber wo kommen diese Berechtigungen her? Eine Vererbung wie Sie sie von Windows her kennen gibt es unter Linux nicht. Hier ist die "umask" für die Vergabe der Berechtigungen eines neuen Eintrags im Dateisystem verantwortlich. Sie können sich die Umask mit dem gleichnamigen Kommando anzeigen lassen. Hier ein Beispiel:
stefan@stefan:~% umask 022
Die drei Stellen der Umask stehen hier für eine Berechtigungszuordnungen. Die erste Stelle für "user", die zweite für "group" und die dritte für "other". Die Umask zeigt an, welche Rechte beim Anlegen eines neuen Eintrags im Dateisystem NICHT vergeben werden. Der Besitzer erhält immer alle Rechte, die besitzenden Gruppe alles außer dem Schreibrecht, genau wie der Rest der Welt. Das bedeutet in der Standardeinstellung kann der Rest der Welt immer in alle Verzeichnisse wechseln und sich den Inhalt aller Dateien anzeigen lassen. Jeder Anwender kann über die Kommandozeile die Einstellung der Umask mit dem Kommando "umask <wert>" selbst anpassen. Später in diesem Artikel werde ich noch auf die Planung eines Berechtigungskonzeptes eingehen, dabei werde ich zeigen, wie man die Umask auch systemweit setzen können. Doch sehen wir uns einmal je einen neuen Eintrag für eine Datei und ein Verzeichnis an und vergleichen dieses mit der gesetzten Umask:
stefan@stefan:~% ls -l insgesamt 4 -rw-r--r-- 1 stefan users 0 Aug 4 11:34 datei1 drwxr-xr-x 2 stefan users 4096 Aug 4 11:34 verzeichnis1
Hier sieht man, dass die Berechtigungen am Verzeichnis mit der Umask übereinstimmen. Der Gruppe und dem Rest der Welt wurde das Schreibrecht nicht vergeben. Der Besitzer hat alle Rechte. Aber was ist mit der Datei? Da fehlt bei allen drei Berechtigungszuordnungen das Execute-Recht. Das ist auch korrekt so! Denn das Betriebssystem überprüft beim Anlegen einer neuen Datei, ob es überhaupt Sinn macht, das Execute-Rechte an der Datei zu setzen. Bei allen nicht-binär-Dateien macht das Setzen des Execute-Rechts auch keinen Sinn, also setzt das System das Recht auch nicht. Nur wenn Sie einen Quellcode kompilieren und dabei eine ausführbare Datei entsteht, dann wird auch das Execute-Recht entsprechend der Umask gesetzt.
Wie werden Rechte gesetzt?
Nach dem Sie jetzt eine Einführung zu den Rechten erhalten haben, will ich jetzt erklären, wie die Rechte gesetzt werden und wer alles Rechte setzen kann. Auch das Ändern der besitzenden Gruppe und des Besitzer will ich in diesem Abschnitt erklären.
Die Rechte an einem Eintrag können immer vom "root" und dem Besitzer einer Datei geändert werden. Zum Ändern der Rechte wird das Kommando "chmod" verwendet. Das Kommando "chmod" kann dabei auf zwei verschiedene Arten angewendet werden: Einmal gibt es die relative Vergabe der Berechtigungen, bei der immer die derzeitige Berechtigung geändert wird. Dann gibt es noch die absolute Vergabe der Berechtigungen, bei der der komplette Satz an Berechtigungen für alle Berechtigungszuordnungen neu erstellt wird.
Relative Vergabe der Rechte im Dateisystem
Bei der relativen Vergabe der Berechtigungen können Sie jedes einzelne Recht für sich vergeben. Hier sehen Sie einige Beispiele:
stefan@stefan:~% chmod u+x datei1 stefan@stefan:~% ls -l datei1 -rwxr--r-- 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod g-r,o-r datei1 stefan@stefan:~% ls -l datei1 -rwx------ 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod a+r datei1 stefan@stefan:~% ls -l datei1 -rwxr--r-- 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod a+rx datei1 stefan@stefan:~% ls -l datei1 -rwxr-xr-x 1 stefan users 0 Aug 4 11:34 datei1
Wie Sie an den Beispielen sehen, können Sie jedes Recht einzeln setzen. Wenn Sie ein Recht zum Beispiel mit "chmod u+x datei1" ändern wollen, aber der Besitzer bereits das Execute-Recht an der Datei hat, ändert sich nichts. Auch sehen Sie in den Beispielen, dass Sie mit der Option "a+r" oder "a-r" ein oder mehrere Rechte für alle Berechtigungszuordnungen gleichzeitig ändern können.
Absolute Vergabe der Rechte im Dateisystem
Dabei gehen Sie ganz anders vor. Sie überlegen sich, welche Rechte Sie für alle drei Berechtigungszuordnungen vergeben wollen, diese rechnen Sie dann in den entsprechenden dreistelligen Oktalwert um und vergeben dann die Rechte für den Eintrag komplett neu. Als Beispiel:
stefan@stefan:~% ls -l datei1 -rwxr-xr-x 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod 600 datei1 stefan@stefan:~% ls -l datei1 -rw------- 1 stefan users 0 Aug 4 11:34 datei
Hier spielt es keine Rolle, welche Rechte vorher auf dem Eintrag gesetzt waren, alle Rechte werden überschrieben.
Ändern der besitzenden Gruppe
Die besitzende Gruppe kann sowohl vom "root" als auch vom Besitzer eines Eintrags geändert werden. Wobei es für den Besitzer eine Einschränkung gibt: Er kann einen Eintrag des Dateisystems nur an Gruppen übergeben, in denen er auch Mitglied ist. Für die Änderung der besitzenden Gruppe verwenden Sie das Kommando "chgrp". Das Beispiel zeigt, wie der Gruppenbesitz geändert wird:
stefan@stefan:~% chgrp cdrom datei1 stefan@stefan:~% ls -l datei1 -rw------- 1 stefan cdrom 0 Aug 4 11:34 datei1
Ändern des Besitzers
Den Besitzer eines Eintrages im Dateisystem - gleich ob Datei oder Verzeichnis - kann nur der "root" ändern. Mit dem Kommando "chown" kann der "root" nicht nur den Besitzer ändern, sondern auch gleichzeitig die besitzenden Gruppe. Auch hierfür einige Beispiele:
root@stefan:~# chown stka datei1 root@stefan:~# ls -l datei1 -rw------- 1 stka cdrom 0 Aug 4 11:34 datei1 root@stefan:~# chown stefan:users datei1 root@stefan:~# ls -l datei1 -rw------- 1 stefan users 0 Aug 4 11:34 datei1
Wie Sie sehen, wurde dieser Vorgang als Benutzer "root" durchgeführt.
Special Bits
Bis zu diesem Punkt ist das Thema für viele von Ihnen mehr oder weniger bekannt. Jetzt kommt die erste Erweiterung der Berechtigungen. In den letzten Abschnitten habe ich immer von drei Oktalgruppen für die Berechtigungen gesprochen. Aber es gibt vier dieser Gruppen. Vor den eigentlichen Dateisystemberechtigungen steht eine vierte Gruppe bestehend aus drei Bits, die zusätzliche Rechte geben oder auch Rechte nehmen kann. Die folgende Tabelle zeigt eine Übersicht der Bits:
Rechte Binärwerte Oktalwert ------------------------------------------ SUID 2^2 4 SGID 2^1 2 Sticky Bit 2^0 1
Das SUID-Bit
Werfen wir doch einmal einen Blick auf die Rechte die an der Datei "/etc/shadow" vergeben sind:
stefan@stefan:~% ls -l /etc/shadow -rw-r----- 1 root shadow 1360 Mai 27 08:52 /etc/shadow
Da sehen Sie, dass der "root" Lese- und Schreibrecht hat und die Gruppe "shadow" nur das Leserecht. In dieser Datei befinden sich die Passwortinformationen aller Benutzer des lokalen Systems. Nur aufgrund der Rechte an der Datei sieht es so aus, als hätte ein "normaler" Benutzer keine Rechte an dieser Datei. In dieser Datei befindet sich aber das Passwort eines jeden Benutzers. Ein Benutzer kann aber sein Passwort mit dem Kommando "passwd" ändern und greift damit schreibend auf die Datei zu. Wie kann das sein? Schauen wir deshalb mal auf die Berechtigungen des Programms "/usr/bin/passwd":
stefan@stefan:~% ls -l /usr/bin/passwd -rwsr-xr-x 1 root root 47032 Jul 15 21:29 /usr/bin/passwd
Da fällt auf, dass an der Stelle, wo sonst beim Besitzer ein "x" steht, jetzt ein "s" steht. Dieses kleine "s" zeigt an, dass das SUID-Bit gesetzt ist. Was passiert jetzt, wenn ein "normaler" Benutzer das Programm "passwd" aufruft um sein Passwort zu ändern? Das System prüft, ob der Benutzer das Recht hat, das Programm zu starten. Da der Benutzer über "other" die Rechte "r-x" besitzt, kann der Benutzer das Programm aufrufen. Jetzt prüft das System zusätzlich, ob das SUID-Bit gesetzt ist. Ist das der Fall, wie bei dem Programm "passwd", erhält der Benutzer ein ZUSÄTZLICHE UID, nämlich die UID des Besitzers des Programms. Damit hat der Benutzer für die Laufzeit des Programms zwei UIDs, seine
eigene und die des "root". Da der "root" Schreibrechte an der Datei "/etc/passwd" hat, kann der Benutzer jetzt sein Passwort ändern. Programme, bei denen das SUID-Bit gesetzt ist, lassen sich nicht im Hintergrund starten. Das wäre auch fatal, da dann der Benutzer im Vordergrund "root"-Rechte hätte.
Das Setzen des SUID-Bits ist nur sinnvoll auf Binärdateien. Das Recht können Sie mit dem Kommando "chmod u+s <Programm>" setzen und entfernen mit "chmod u-s <Programm>". Damit das SUID-Bit genutzt werden kann, muss auch immer für den
Besitzer das "x"-Bit gesetzt sein. Da nach dem Setzen des SUID-Bits an der Stelle des "x" jetzt immer ein "s" steht, können Sie das gesetzte "x"-Bit daran erkennen, dass es sich bei dem "s" um ein kleines "s" handelt. Würde an der Stelle ein großes "S" stehen, wäre das "x"-Bit nicht gesetzt.
Das SGID-Bit
Mit dem SGID-Bit können Sie die Verwaltung der Rechtestruktur in Ihrem Dateisystem beeinflussen. Normalerweise gibt es bei Linux keine Vererbung der Berechtigungen im Dateisystem, aber durch den Einsatz des SGID-Bits können Sie das in einem bestimmten Rahmen ändern. Wenn Sie an einem Verzeichnis das SGID-Bit setzen, wird ab diesem Zeitpunkt jeder neue Eintrag unterhalb des Verzeichnisses immer der Gruppe gehören, die in diesem Verzeichnis als besitzende Gruppe eingetragen ist. Das SGID-Bit vererbt sich auch auf alle neu erstellten Unterverzeichnisse, die nach dem Setzen des SGID-Bits erzeugt werden. Wenn Sie auf Ihrer Verzeichnisstruktur das SGID-Bit an den einzelnen Abteilungsverzeichnissen setzen, gehören anschließend alle Einträge der entsprechenden Gruppe, ohne dass ein Benutzer seine Standardgruppe ändern müsste. Zusammen mit einer angepassten Umask können Sie dann bestimmte Verzeichnisse gezielt einer Gruppe zuordnen und die Rechte bestimmen. Mehr dazu folgt später im praktischen Teil dieses Artikels.
Der Einsatz des SGID-Bits ist nur sinnvoll, wenn es auf Verzeichnisse gesetzt wird. Es wird mit dem Kommando "chmod g+s <Verzeichnis>" gesetzt. Hier ein Beispiel:
stefan@stefan:~% chmod g+s verzeichnis1 stefan@stefan:~% ls -ld verzeichnis1 drwxr-sr-x 2 stefan users 4096 Aug 4 11:34 verzeichnis1 stefan@stefan:~% chgrp cdrom verzeichnis1 stefan@stefan:ueb~% cd verzeichnis1 stefan@stefan:~/verzeichnis1% mkdir verzeichnis1a stefan@stefan:~/verzeichnis1% ls -ld verzeichnis1a drwxr-sr-x 2 stefan cdrom 4096 Aug 4 17:31 verzeichnis1a
Hier sehen Sie, dass das neue Verzeichnis der neu zugeordneten Gruppe "cdrom" gehört und das SGID-Bit am Verzeichnis "verzeichnis1" gesetzt wurde. Auch das neue Unterverzeichnis "verzeichnis1/verzeichnis1a" hat das SGID-Bit gesetzt.
Das Sticky-Bit
Der Name dieses Bits stammt von seiner ursprünglichen Bedeutung. Wurde dieses Bit auf ein ausführbares Programm vom "root" gesetzt, dann blieb das Programm nach Beendigung im Arbeitsspeicher "kleben". Beim nächsten Aufruf wurde das Programm dann direkt aus dem Arbeitsspeicher gestartet. Dadurch wurde der Startvorgang des Programms beschleunigt. Linux nutzt das Sticky-Bit aber anders. Wenn Sie das Sticky-Bit an einem Verzeichnis setzen, kann nur noch der Besitzer einer Datei in dem Verzeichnis diese auch löschen. Auch wenn ein anderer Benutzer am Verzeichnis die Rechte "r,w,x" besitzt, ist er nicht berechtigt eine Datei zu löschen. Das Sticky-Bit macht nur Sinn, wenn es auf Verzeichnissen gesetzt wird. Das Sticky-Bit setzen Sie mit dem Kommando "chmod o+t <Verzeichnis>". Ein Beispiel:
stefan@stefan:~% mkdir verzeichnis2 stefan@stefan:~% chmod g+w,o+t verzeichnis2 stefan@stefan:~% ls -ld verzeichnis2 drwxrwxr-t 2 stefan users 4096 Aug 4 18:02 verzeichnis2 stefan@stefan:~% cd verzeichnis2 stefan@stefan:~/verzeichnis2% touch datei2 stefan@stefan:~/verzeichnis2% ls -l datei2 -rw-r--r-- 1 stefan users 0 Aug 4 18:04 datei2 stefan@stefan:berechtigungen-ia/verzeichnis2% su stka Passwort: stka@stefan:/home/stefan/verzeichnis2% rm datei2 rm: Normale leere Datei (schreibgeschützt) »datei2“ entfernen? y rm: das Entfernen von »datei2“ ist nicht möglich: Vorgang nicht zulässig
Sie sehen hier, obwohl der Benutzer "stka" alle Rechte am Verzeichnis "verzeichnis2" über die Gruppe "users" (in der er Mitglied ist) erhält, kann er die Datei in dem Verzeichnis nicht löschen. Auch die Meldung ist eine ganz andere, als wenn ihm das Recht fehlen würde. Hier wird jetzt auf Grund des Sticky-Bits der Vorgang untersagt. Das Sticky-Bit ist ein sehr gutes Mittel, um in Verzeichnissen auf die mehrere Benutzer Zugriff haben, ein versehentliches Löschen von Dateien durch Nichtbesitzer zu verhindern. Das Bit schützt aber nicht vor der Veränderung des Inhalts von Dateien.
Die erweiterten POSIX-ACLs
Aber was tun Sie, wenn Sie an einem Verzeichnis unterschiedliche Rechte für unterschiedliche Gruppen vergeben wollen? Diese Aufgabe können Sie nicht mehr mit den einfachen Dateisystemrechten lösen. Dafür benötigen Sie die Access Control Lists (ACL). Hier geht es darum, die Dateisystemrechte zu erweitern. Mithilfe der ACL ist es möglich, dass mehrere Gruppen oder Benutzer an einer Datei oder einem Verzeichnis unterschiedliche Rechte erhalten. Damit Sie die ACLs nutzen können, müssen Sie als Erstes das Dateisystem für die ACL-Unterstützung anpassen. Alle gängigen Dateisysteme wie ext2, ext3, ext4, reiserfs und xfs unterstützen ACLs. Aber die ACLs müssen eventuell beim Mounten des Dateisystems als Option mit angegeben werden. Sie können die entsprechende Option natürlich auch direkt in dem Eintrag der "/etc/fstab" mit angeben, so werden die ACLs auch bei einem Systemstart sofort wieder aktiviert.
Warum nur "eventuell"? Weil bei vielen aktuellen Distributionen die Dateisysteme schon so kompiliert wurden, dass sie ACLs unterstützen. Wenn Sie die in diesem Abschnitt besprochenen Beispiele auf Ihrem System nachvollziehen können, ohne die Datei "/etc/fstab" anpassen zu müssen, dann unterstützt Ihr Dateisystem die ACLs ohne dass Sie weitere Optionen angeben müssen. Sollte das nicht der Fall sein, müssen Sie die Einträge in Ihrer "/etc/fstab" wie folgt anpassen:
/dev/hdb1 /daten ext4 errors=remount-ro,acl 0 0
Hier wurde für eine Datenpartition die Option "acl" hinzugefügt. Nach einem "remount" mit dem Kommando "mount -o remount,rw /daten" stehen dann auf dieser Partition die ACLs zur Verfügung. Bei den ACLs wird zwischen den einfache ACLs und den default ACLs unterschieden. Zur Verwaltung der ACLs gibt es die Kommandos "setfacl" zum Setzen der ACLs und "getfacl" zum Auslesen der ACLs. Wenn diese Programme auf Ihrem System nicht vorhanden sind, müssen Sie das Paket "acl" nachinstallieren.
Die einfachen ACLs
Einfache ACLs gelten nur für das Verzeichnis oder die Datei, auf die sie angewendet wurden. Die einfachen ACLs werden nicht vererbt. Das folgende Listing zeigt, wie eine ACL auf ein Verzeichnis gesetzt wird:
stefan@stefan:~% mkdir verzeichnis3 stefan@stefan:~% ls -ld verzeichnis3 drwxr-xr-x 2 stefan users 4096 Aug 4 18:51 verzeichnis3 stefan@stefan:~% setfacl -m g:cdrom:rx verzeichnis3 stefan@stefan:~% ls -ld verzeichnis3 drwxr-xr-x+ 2 stefan users 4096 Aug 4 18:51 verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx group::r-x group:cdrom:r-x mask::r-x other::r-x
Im ersten Teil des Beispiels wird ein neues Verzeichnis angelegt und die Rechte aufgelistet. Im zweiten Teil wird dann mit dem Kommando "setfacl -m g:cdrom:rx verzeichnis3" ein ACL gesetzt. Die einzelnen Parameter haben dabei die folgende Bedeutung:
- -m
Mit dieser Option "-m" wird das Kommando "setfacl" angewiesen, die ACL eines Eintrages zu modifizieren. - - g:cdrom:rx verzeichnis3
Eine Gruppe (bestimmt durch den Parameter "g") "cdrom" erhält die Rechte "rx" am "verzeichnis3"
Die Reihenfolge der Parameter muss dabei eingehalten werden.
Im dritten Teil werden die Rechte des Verzeichnisses "verzeichnis3" nochmal aufgelistet. Hier sehen Sie, dass nach den Rechten jetzt ein "+" zu sehen ist. Dieses "+" weist darauf hin, dass an dem Eintrag im Dateisystem ACLs gesetzt sind. Dann wird die ACL des Verzeichnisses "verzeichnis3" aufgelistet. Hier sehen Sie jetzt, dass neben der Gruppe "users" die Gruppe "cdrom" Rechte erhalten hat.
ACHTUNG: Wenn Sie auf einem Eintrag im Dateisystem – egal ob bei einem Verzeichnis oder einer Datei – eine ACL gesetzt haben, dürfen Sie von dem Moment an keine Berechtigungen mehr mit dem Kommando "chmod" ändern. Denn dann ändern Sie nicht mehr die Rechte sondern nur eine ACL-Maske. Diese Maske kann nur Rechte ausfiltern. Sprich: ein Recht, das dort nicht gesetzt ist, kann auch keine Gruppe oder Benutzer erhalten.
Um das Verhalten zu verdeutlichen, folgt hier ein Beispiel:
stefan@stefan:~% chmod g-r verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx group::r-x #effective:--x group:cdrom:r-x #effective:--x mask::--x other::r-x
Hier sehen Sie, dass die Gruppen nur noch das effektive Recht "x" besitzen, durch die Maske wird das "r"-Recht ausgefiltert. Wenn das Recht mit "chmod" wieder zurückgesetzt wird, wird auch die Maske wieder zurückgesetzt. Was passiert aber, wenn die besitzende Gruppe (so wie im Beispiel) nur die Rechte "r-x" besitzt und Sie für eine andere Gruppe die Rechte "rwx" setzen wollen? Denn in der Standardberechtigung fehlt ja das "w"-Recht. Da es sich bei den Berechtigungen aber um einen Filter handelt, müsste das "w"-Recht auch für eine andere Gruppe nicht wirksam sein. Aber das ist nicht so, wie das folgende Listing zeigt:
stefan@stefan:~% setfacl -m g:cdrom:rwx verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx group::r-x group:cdrom:rwx mask::rwx other::r-x
Obwohl die besitzende Gruppe nur die Rechte "r-x" besitzt, hat die Gruppe "cdrom" alle Rechte am Verzeichnis. Erst eine nachträgliche Veränderung der Berechtigungsliste verändert die Maske. Selbstverständlich können Sie auch einem einzelnen Benutzer Rechte über ACLs vergeben. Das Listing zeigt diesen Vorgang:
stefan@stefan:~% setfacl -m u:stka:rwx verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx user:stka:rwx group::r-x group:cdrom:rwx mask::rwx other::r-x
Wenn Sie jetzt in dem Verzeichnis eine neue Datei oder Verzeichnis erstellen, werden Sie feststellen, dass die ACLs nicht auf die neuen Einträge übernommen wurden. Damit die ACLs auf neue Einträge vererbt werden, müssen Sie die "defaults ACLs" an Verzeichnissen setzen.
Die default ACLs
Bis jetzt waren alle ACLs immer nur für den Eintrag gültig, auf dem Sie die ACL gesetzt hatten. Mit den default ACLs können Sie jetzt Berechtigungen auf ein Verzeichnis setzen, die sich dann an alle darunter neu erstellten Einträge vererben. Das Listing zeigt wie Sie default ACLs setzen können:
stefan@stefan:~% mkdir verz-def-acl stefan@stefan:~% setfacl -d -m g:cdrom:rwx verz-def-acl stefan@stefan:~% ls -ld verz-def-acl drwxr-xr-x+ 2 stefan users 4096 Aug 6 10:57 verz-def-acl stefan@stefan:~% getfacl verz-def-acl # file: verz-def-acl # owner: stefan # group: users user::rwx group::r-x other::r-x default:user::rwx default:group::r-x default:group:cdrom:rwx default:mask::rwx default:other::r-x
Mit der setfacl-Option "-d" erstellen Sie ein default ACL. Wenn Sie sich das Verzeichnis mit "ls" anzeigen lassen, sehen Sie auch hier wieder das Pluszeichen am Ende der Rechteliste, welches auf das Vorhandensein von ACL hinweist. Lassen Sie sich jetzt die ACLs mittels "getfacl" anzeigen, sehen Sie, dass alle ACLs als "default ACLs" eingetragen wurden. Wenn Sie jetzt in dem Verzeichnis ein neues Verzeichnis oder eine neue Datei anlegen, werden diese Einträge die ACLs übernehmen. In nächsten Listing möchte ich Sie noch einmal auf das Verhalten beim Anlegen einer Datei hinsichtlich des x-Rechts aufmerksam machen. In den "default ACLs" ist ja das x-Recht immer mit gesetzt und wird somit auf alle neuen Einträge übernommen. Auch auf Dateien werden diese "default ACLs" gesetzt. Wenn Sie jetzt aber eine leere Datei oder eine Datei einer Anwendung erstellen, vergibt das Betriebssystem das x-Recht nicht an diese Datei. In den ACLs ist es aber gesetzt, deshalb sehen Sie bei dem Aufruf von "getfacl" den Hinweis "effective". Das ist kein Fehler, das ist das richtige Verhalten.
stefan@stefan:~% touch dat-acl stefan@stefan:~% getfacl dat-acl # file: dat-acl # owner: stefan # group: users user::rw- group::r-x #effective:r-- group:cdrom:rwx #effective:rw- mask::rw- other::r--
Löschen von ACLs
Sowohl die einfachen, als auch die default ACLs löschen Sie mit dem Kommando "setfacl". Beim Entfernen der ACLs wird zwischen den unterschiedlichen ACLs unterschieden. Sie müssen vor dem Löschen wissen, ob Sie ein einfache oder eine default ACL entfernen wollen. Das folgende Listing zeigt den Vorgang des Löschens einer default ACL:
stefan@stefan:~/verz-def-acl% setfacl -k verz-acl stefan@stefan:~/verz-def-acl% getfacl verz-acl # file: verz-acl # owner: stefan # group: users user::rwx group::r-x group:cdrom:rwx mask::rwx other::r-x stefan@stefan:berechtigungen-ia/verz-def-acl% ls -ld verz-acl drwxrwxr-x+ 2 stefan users 4096 Aug 6 11:05 verz-acl
Durch die Option "-k" werden alle default ACLs des Eintrags gelöscht, die einfachen ACLs bleiben erhalten. Mit der Option "-b" löschen Sie die einfachen ACLs:
stefan@stefan:~/verz-def-acl% setfacl -b verz-acl stefan@stefan:~/verz-def-acl% ls -ld verz-acl drwxr-xr-x 2 stefan users 4096 Aug 6 11:05 verz-acl
Und dann ist da noch das Folgende
Bis zu diesem Zeitpunkt haben wir immer nur ACLs auf einzelne Einträge gesetzt oder entfernt. Selbstverständlich können Sie die ACLs auch rekursiv über einen ganzen Teilbaum setzen oder löschen. Auch ein Sichern der ACLs mittels "getfacl" können Sie rekursiv durchführen und diese Sicherung später mittels "setfacl" wieder einspielen. Das ist besonders dann wichtig, wenn Sie eine Backup-Software einsetzen, die keine ACLs sichern kann. Dann können Sie die ACLs getrennt in eine Datei sichern und anschließend – bei einem eventuellen Recovery des Dateisystems – aus der Datei wieder einspielen. Sowohl das Kommando "setfacl" als auch das Kommando "getfacl" kennen die Option "-R" für das rekursive Löschen oder Anzeigen. Im folgenden Listing sehen Sie ein paar Beispiele für die Verwendung von "setfacl" und "getfacl":
stefan@stefan:~% getfacl -R verz-def-acl stefan@stefan:~% getfacl -R verz-def-acl > sicherung.acl stefan@stefan:~% setfacl -R -m g:cdrom:rwx verz-def-acl stefan@stefan:~% setfacl --restore=sicherung.acl
Im ersten Beispiel werden alle ACLs aller Einträge angezeigt. Im zweiten Beispiel werden die Einträge in eine Datei gesichert. Beim dritten Beispiel werden alle Einträge ab dem angegeben Verzeichnis mit einer ACL belegt. Das vierte Beispiel zeigt dann, wie Sie die ACLs aus einer Datei wieder einspielen können. Wenn Sie jetzt die ACLs in Ihrem Dateisystem anwenden wollen, dann stellen Sie schnell fest, dass Dateien und Verzeichnisse unterschiedliche ACLs benötigen. Zum Beispiel braucht ein Textdokument kein x-Recht, aber ein Verzeichnis benötigt dieses Recht auf jeden Fall, denn sonst kann nicht in das Verzeichnis gewechselt werden. Deshalb können Sie das Kommando "setfacl" sehr gut zusammen mit dem Kommando "find" einsetzen. Im nächsten Listing zeige ich Ihnen, wie Sie für alle Dateien und Verzeichnisse ab einem bestimmten Punkt ACLs setzen können:
stefan@stefan:~% find . -type d -exec setfacl -d -m g:cdrom:rwx {} \;
stefan@stefan:~% find . -type f -exec setfacl -m g:cdrom:r {} \;
Im ersten Beispiel werden alle Verzeichnisse ab dem aktuellen Verzeichnis gesucht und anschließend wird für jedes Verzeichnis die entsprechende default ACL gesetzt. Im zweiten Beispiel wird nach allen Dateien gesucht und die einfache ACL gesetzt. Die Option "-d" darf hier nicht verwendet werden, da sich default ACLs nur auf Verzeichnisse setzen lassen. Verwenden Sie trotzdem die Option "-d", werden für die Dateien Fehlermeldungen ausgeworfen.
Zusammen mit den Berechtigungen, den "special-Bits" und den ACLs stehen Ihnen jetzt eine Vielzahl von Möglichkeiten zur Verfügung, die Rechte in Ihrem Dateisystem gezielt zu setzen.
Die erweiterten Attribute
Auch Linux kennt im Dateisystem erweiterte Attribute mit denen Sie bestimmte Einschränkungen beim Zugriff auf Dateien einrichten können. Diese erweiterten Attribute möchte ich an dieser Stelle vorstellen. Um die Attribute verwenden zu können muss das Dateisystem vorbereitet werden. Denn auch für die Attribute gibt es eine Mountoption, die Sie wieder bei einigen älteren Distributionen in der Datei "/etc/fstab" setzen müssen. Das Listing zeigt Ihnen den angepassten Eintrag in der Datei:
/dev/hdb1 /daten ext4 errors=remount-ro,acl,user_xattr 0 0
Nach einem "remount" des Dateisystems stehen Ihnen dann die erweiterten Attribute zur Verfügung. Die Attribute setzen Sie mit dem Kommando "chattr". Auflisten können Sie die Attribute mit dem Kommando "lsattr", sollten diese Kommandos auf Ihrem System nicht vorhanden sein, müssen Sie das Paket "attr" nachinstallieren.
Bei den Attributen gibt es zwei Gruppen: Die Attribute der einen Gruppe können von "normalen" Benutzern gesetzt werden, die Attribute der anderen Gruppe können nur vom "root" gesetzt werden. Unter den Attributen gibt es einige, die sowieso selten benötigt werden, diese sollen hier nicht betrachtet werden. Aber einige der Attribute können im täglichen Umgang mit Dateisystemrechten nützlich sein. Diese werden ich Ihnen hier erklären.
Attribute, die jeder setzen kann
- Das Attribut "d"
Durch Setzen dieses Attributs verhindern Sie, dass die entsprechende Datei bei einer Datensicherung mit dem Kommando "dump" mitgesichert wird. - Das Attribut "s"
Wenn ein Benutzer dieses Attribut setzt, wird die Datei beim Löschen mit Nullen überschrieben. - Das Attribut "A"
Wenn Sie das Attribut "A" setzen, wird die "atime" der Datei nicht verändert. Das kann die Performance beim Schreiben erhöhen. Besser ist es aber, hier die Option "noatime" für das gesamte Dateisystem in der Datei "/etc/fstab" zu setzen.
Attribute die nur der "root" setzen kann
- Das Attribut "a"
Wenn Sie als "root" dieses Attribut auf eine Datei setzen, kann der Inhalt der Datei nicht mehr geändertwerden, es können nur noch Daten an die Datei angehängt werden. Hier sehen Sie dazu ein Beispiel:root@stefan:~# touch datei1.txt root@stefan:~# chattr +a datei1.txt root@stefan:~# lsattr datei1.txt -----a------------- datei1.txt root@stefan:~# echo "Eine neue Zeile" > datei1.txt -bash: datei1.txt: Die Operation ist nicht erlaubt root@stefan:~# echo "Eine neue Zeile anhängen " >> datei1.txt
Mit dem ersten Kommando wird einfach eine leere Datei erzeugt, bei der im zweiten Schritt das Attribut "a" gesetzt wird. Im Anschluss wird versucht, eine Zeile in die Datei mit einer einfachen Umleitung zu schreiben. Diese Operation wird aufgrund des Attributs verboten. Selbst der "root" kann den Inhalt der Datei nicht verändern, solange das Attribute "a" gesetzt ist. Erst im nächsten Schritt wird eine Zeile an die Datei angehängt, und jetzt ist das
Schreiben in die Datei möglich.
- Das Attribut "i"
Durch das Attribut "i" wird die Datei immun gegen das Ändern, Umbenennen und Löschen. Auch der "root" kann eine Datei mit diesem Attribut nicht löschen, ohne vorher das Attribut zurückzusetzen. Auch dazu sehen Sie ein Beispiel: root@stefan:~# chattr +i datei1.txt
root@stefan:~# lsattr datei1.txt ----i-------------- datei1.txt root@stefan:~# echo "Eine zweite Zeile anhängen " >> datei1.txt -bash: datei1.txt: Keine Berechtigung root@stefan:~# ls -l datei1.txt -rw-r--r-- 1 root stefan 27 27. Jul 18:02 datei1.txt root@stefan:~# rm datei1.txt rm: Entfernen von "datei1.txt" nicht möglich: Die Operation ist nicht erlaubt root@stefan:~# mv datei1.txt datei1a.txt mv: Verschieben von "datei1.txt" nach "datei1a.txt" nicht möglich: Die Operation ist nicht erlaubt root@stefan:~# chattr -i datei1.txt root@stefan:~# rm datei1.txt
Alle Aktionen wurden hier als Benutzer "root" durchgeführt. Wie Sie sehen, ist danach keine Aktion mit der Datei mehr möglich. Erst wenn das Attribut von der Datei entfernt wird, kann die Datei wieder gelöscht werden.
Weitere Attribute
Neben diesen Attributen gibt es noch weitere Attribute, die zum Teil experimentell oder nicht von so großer Bedeutung für den täglichen Gebrauch sind. Alle Attribute werden ausführlich in der Manpage zu "chattr" beschrieben. Wenn Sie die Attribute verwenden wollen, sollten Sie immer einen Blick auf diese Manpage werfen, um mögliche Komplikationen zu vermeiden, denn nicht alle Attribute funktionieren in allen Dateisystemen.
Ein praktisches Beispiel
Nach dem im ersten Teil die Grundlagen besprochen wurden, will ich Ihnen jetzt anhand eines Beispiels zeigen, wie Sie die Dateisystemrechte planen können. Natürlich ist es in so einem Artikel nicht möglich, alle Eventualitäten abzudecken, aber eine gewisse Planungsgrundlage kann ich Ihnen hier an die Hand geben. In dem Beispiel werde ich eine Verzeichnisstruktur erstellen, die sich auf ein Unternehmen mit mehreren Abteilungen bezieht, in dem jede Abteilung unterschiedliche Zugriffsrechte auf verschiedene Ordner benötigt. Desweiteren soll ein Verzeichnis für alle Mitarbeiter existieren, das als Austauschverzeichnis für Daten dient und in das alle Mitarbeiter schreiben dürfen, aber nur der Besitzer einer Datei soll diese auch löschen können. Um die Verzeichnisse hier abbilden zu können, werde ich das Kommando "tree" verwenden. Sollte das Kommando bei Ihnen nicht installiert sein, müssen Sie das Paket "tree" nachinstallieren.
Im Beispiel wird alles auf einer lokalen Maschine eingerichtet. In der Praxis werden Sie die Daten auf einem Server verwalten und die Benutzerverwaltung zentral durchführen. Da sich die ACLs und die Dateisystemrechte via NFS auf Clients exportieren lassen, können Sie das Beispiel auch auf einem Fileserver mit einer zentralen Benutzerverwaltung und angebundenen Clients einrichten und testen.
Beschreibung der Umgebung
Die Firma besteht aus drei Abteilungen: Der Verwaltung, der Produktion und der Geschäftsleitung. Jede Abteilung soll ein eigenes Verzeichnis erhalten, in der nur diese Abteilung Schreibrechte haben soll. Die Geschäftsleitung möchte auf allen Abteilungsverzeichnissen das Leserecht haben. Alle Dateien in den Abteilungsverzeichnissen sollen immer der Abteilungsgruppe gehören. Die Rechte aller neuen Einträge sollen immer mit der Umask 007 angelegt werden. Es soll ein Gruppe "mitarbeiter" geben, in der alle Mitarbeiter Mitglied sind. Über die Gruppe sollen die Rechte am Austauschverzeichnis gesteuert werden.
Setzen der Umask
Damit alle Mitarbeiter auf allen Clients die gewünschte Umask von 007 erhalten, müssen Sie, je nach Distribution, entweder direkt die Datei "/etc/profile" oder die Datei "/etc/login.defs" anpassen. Diese Anpassung müssen Sie an jedem Client durchführen.
Einrichten der Verzeichnisstruktur
Um die Berechtigungen gut staffeln zu können, wird ein übergeordnetes Verzeichnis für die Abteilungen eingerichtet. An diesem Verzeichnis erhalten alle Mitarbeiter über die Gruppe "mitarbeiter" die Rechte "rx", damit sie durch das Verzeichnis in das eigentliche Abteilungsverzeichnis wechseln können. Das wäre auf einem Server auch das Verzeichnis, das über NFS an alle Clients freigegeben würde. Das folgende Listing zeigt das Anlegen der Verzeichnisstruktur:
root@stefan:~# mkdir /abteilungen root@stefan:~# cd /abteilungen root@stefan:/abteilungen# mkdir verwaltung produktion geschaeftsleitung root@stefan:/abteilungen# mkdir /alle
Nach dem alle benötigten Verzeichnisse angelegt wurden, zeigt das nächste Listing, wie Sie die entsprechenden Rechte setzen müssen:
root@stefan:/# chmod 750 /abteilungen root@stefan:/# chmod 2770 /abteilungen/* root@stefan:/# chgrp mitarbeiter /abteilungen root@stefan:/# chgrp verwaltung /abteilungen/verwaltung root@stefan:/# chgrp produktion /abteilungen/produktion root@stefan:/# chgrp geschaeftsleitung /abteilungen/geschaeftsleitung root@stefan:/# tree -p abteilungen abteilungen --- [drwxrws---] geschaeftsleitung --- [drwxrws---] produktion --- [drwxrws---] verwaltung root@stefan:/# chgrp mitarbeiter /alle root@stefan:/# chmod 3770 /alle root@stefan:/# ls -ld /alle drwxrws--T 2 root mitarbeiter 4096 Aug 10 13:04 /alle
Jetzt kann jede Abteilung in ihrem Verzeichnis Daten speichern. Durch das gesetzte SGID-Bit gehören alle Dateien immer der Abteilungsgruppe. Über "other" werden keine Rechte vergeben. Am Verzeichnis "/alle" haben alle Mitarbeiter die Rechte "rwx". Dadurch können sie Einträge erzeugen und Inhalte ändern. Aber nur die Einträge, die ihnen gehören können sie löschen oder umbenennen. Jetzt fehlt nur noch, dass die Geschäftsleitung an allen anderen Abteilungsverzeichnissen das Leserecht an allen Einträge erhält. Das steuern Sie über die default ACLs an den Verzeichnissen. Das Listing zeigt die entsprechenden
Kommandos:
root@stefan:/# setfacl -d -m g:geschaeftsleitung:rx /abteilungen/verwaltung root@stefan:/# setfacl -d -m g:geschaeftsleitung:rx /abteilungen/produktion
Jetzt können alle Mitglieder der Gruppe "geschaeftsleitung" in allen Verzeichnissen mindestens lesen. Dadurch, dass die ACLs als default ACLs gesetzt wurden, vererben sich die ACLs immer weiter und auch in neu angelegten Unterverzeichnissen hat die Geschäftsleitung die gewünschten Rechte.
Fazit
Ich hoffe, ich konnte Ihnen mit diesem kleinen Artikel zum Thema Dateisystemberechtigungen etwas helfen, in Zukunft einfacher Verzeichnisstrukturen für Mitarbeiter bereitzustellen und diese mit den benötigten Rechten und ACLs zu versehen.
Autor
Publikationen
- Shell-Programmierung: Das umfassende Handbuch
- Linux-Server: Das Administrationshandbuch
- Linux-Server: Das umfassende Handbuch
- Samba 4: Das Handbuch für Administratoren
SSH-Tunnel
How To Run A Server At Home Without An IPv4 Address
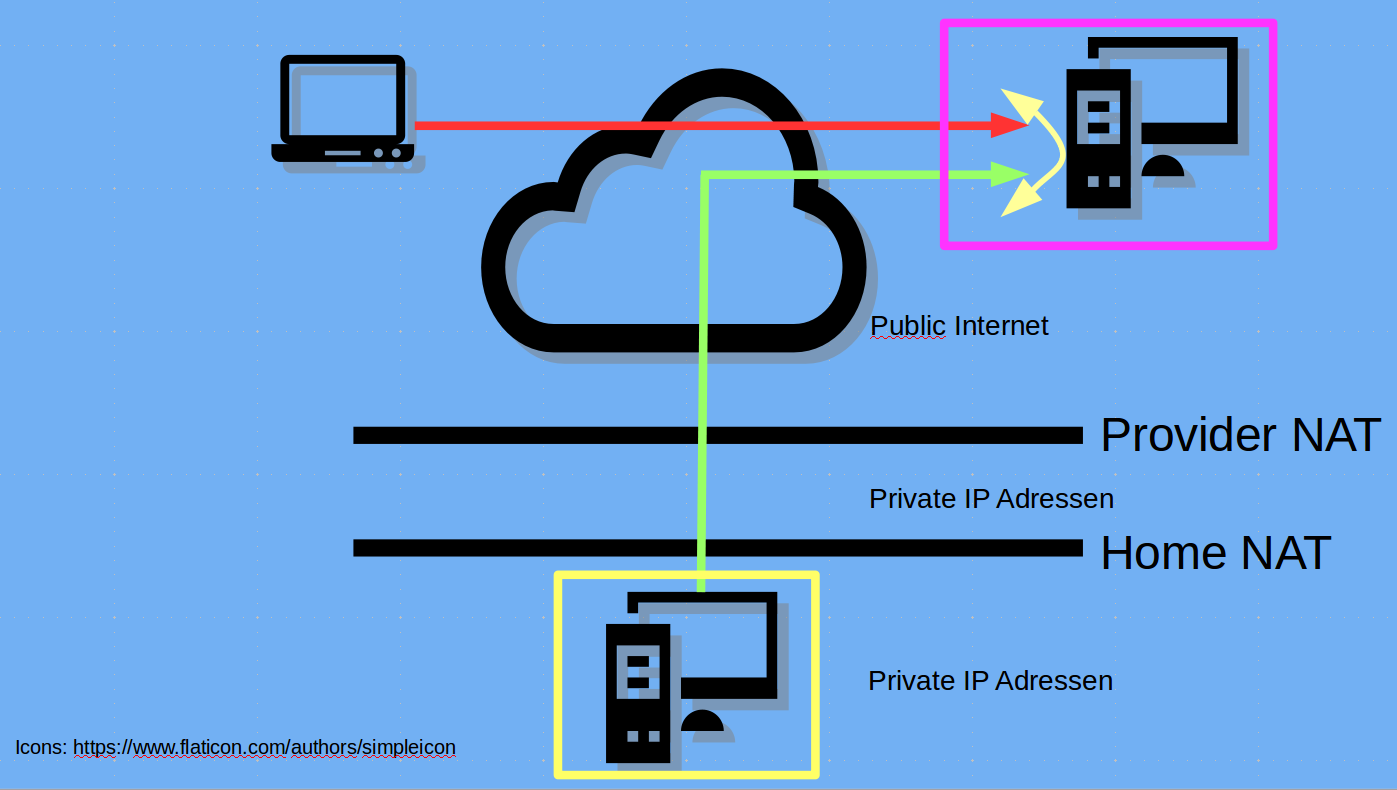
Once upon a time the Internet was bidirectional and everyone could run a server at their end. Unfortunately, these days are long gone and many ISPs today, especially cable providers, do not assign a public IPv4 address to their customers. Not even when you ask them nicely. Not even for money, unless you are a business customer who is willing to pay through the nose for the privilege. Fortunately, there is a way to run servers at home and make them accessible to the outside world and an easy one at that. The following text and shell commands are from a talk I gave at GPN19 (in German).
The program that makes this straight forward is ssh, or secure shell. Despite its name, ssh is the Swiss army knife when it comes establishing tunnels between different parts of the Internet through which TCP packets can be forwarded.
So making a server at home available despite a provider double NAT can be done by renting a server with a public IP address, preferably from a local cloud provider and then use it for forwarding packets. In my case, I pay €3 a month for such a server, that, by the way, I also use to run this blog on!
The image on the left shows the principle and the following commands show how the tunnel is configured. In the example, the server at home uses TCP port 7324 but should be accessible from the Internet on TCP port 8080. One would usually use the same ports but I thought an example with different ports is better to show if the local or the remote port is meant in my example below. In addition I use TCP port 39122 for ssh on the remote server instead of port 22 as my access log would otherwise be full with connection requests from bots on a mission.
Once things are working, autossh and crontab can be used to put the tunnel process into the background, to restore the tunnel automatically when it fails and to even survive reboots without administrative action. Have fun!
##### Test Apache, local works, remote does not, no tunnel yet.
http://localhost:7324/apollo.jpg
http://remote-server.gpn-demo.de:8080/apollo.jpg
#home-srv: Generate ssh keys for normal user.
#These are used to authenticate on the remote server
#
ssh-keygen -t rsa -b 4096 -c "user@clienthost"
#home-srv: Display ssh public key and copy it
#
cat ~/.ssh/id_rsa.pub
#remote-srv: Put public key into root account's
#'authorized_keys'
#
sudo nano /root/.ssh/authorized_keys
#remote-srv: Configure SSH daemon to:
# - allow tunnel ports to be used by incoming requests
# from the Internet (Gateway)
# - timeouts for stale connections
sudo nano /etc/ssh/sshd_config
GatewayPorts yes
ClientAliveInterval 60
ClientAliveCountMax=2
sudo service sshd restart
#remote-server: Open second shell and show open tcp ports
#
watch -n 0.5 "netstat -tulpn"
#home-server: Test establishment of tunnel from
#home-srv (local) port 7324 to remote-srv 8080. First time
#around, fingerprint needs to be confirmed!
#
ssh -p 39122 -N -R 8080:localhost:7324 root@remote-server.gpn-demo.de
##### Test Apache, local works and remote works too now!
#CTRL-C ssh command
##### Test Apache, local works, remote does NOT work because tunnel is gone!
#home-server: Once working, use same command with '-f' option to put to the background
#
autossh -M 0 -f -o ConnectTimeout=10 -o ServerAliveInterval=60 -o ServerAliveCountMax=2 \
-p 39122 -N -R 8080:localhost:7324 root@remote-server.gpn-demo.de
#Simulate ERROR scenario - kill ssh connection on remote side
#remote-server: Terminate process that handles port
#8080 (see pid in 'watch')
#
kill XXXX
##### Test Apache, local works, remote still works!
###### Finally
#home-server: Run autossh command on startup
#
crontab -e
### IMPORTANT: make this ONE line, crontab doesn't
### like the backslash!
@reboot autossh -M 0 -f -o ConnectTimeout=10 -o ServerAliveInterval=60 -o ServerAliveCountMax=2 ......
-p 39122 -N -R 8080:localhost:7324 root@remote-server.gpn-demo.de
DONE!!!https://blog.wirelessmoves.com/2019/06/how-to-run-a-server-at-home-without-an-ipv4-address.html
Rapimc:
SSH-Tunnel raspimc: (root crontab)
@reboot sleep 20 &&/usr/bin/mount_all
@reboot autossh -M 0 -f -o ConnectTimeout=10 -o ServerAliveInterval=60 -o ServerAliveCountMax=2 -p 48153 -N -R 8081:localhost:22 root@meet.wkmimnl.de
@reboot autossh -M 0 -f -o ConnectTimeout=10 -o ServerAliveInterval=60 -o ServerAliveCountMax=2 -p 48153 -N -R 8082:localhost:8080 root@meet.wkmimnl.de
@reboot autossh -M 0 -f -o ConnectTimeout=10 -o ServerAliveInterval=60 -o ServerAliveCountMax=2 -p 48153 -N -R 8083:localhost:6875 root@meet.wkmimnl.de
Howtos
How to Create Local Debian Repository
Why to create a private Debian repository ?
So that to gain more control while updating and upgrading your .deb files, to be able to install exactly the files you used in your test environment, and, what is also important – to avoid so called “dependency hell”.
Follow the steps below to create a local Debian repository, that is recognized by Apt. Apt will use .deb files from the private repository and resolve the associated dependencies when you run the command to install the packages.
1. Install the dpkg-scanpackages tool
To do so, run the following command as root:
apt-get install dpkg-dev
2. Then, create repository directory and place packages there:
mkdir /path/to/repository
cp /path/to/packages /path/to/repository
3. Run “dpkg-scanpackages”
Switch to the repository directory and invoke the dpkg-scanpackages there:
cd /path/to/repository
dpkg-scanpackages -m . > Packages
This creates the Packages file holding the metadata for all packages in the newly created repository.
It is also possible to create a gzipped version of the Packages file - Packages.gz:
cd /path/to/repository
dpkg-scanpackages -m . | gzip > Packages.gz
4. Create a Debian configuration file for the repository
The configuration file (for example myrepo.list) should be placed under the /etc/apt/sources.list.d/ directory and may look like:
deb [trusted=yes] file:/path/to/repository /
In the case when you’d like to share your repository over the network, e.g. to put it under http://your-site.com, the configuration file may look like:
deb [trusted=yes] http://your-site.com/your/repository/ /
or just use RpmDeb capabilities to create, host and distribute your packages worldwide without the neccessity to set up and maintain infrastructure.
OpenMediaVault - Komplettanleitung zur Installation und Konfiguration
Anmeldung nach Upgrade 7->8 : 502 - Bad Gateway
=> omv-salt deploy list-dirty
=> omv-salt deploy run $
Alpine IGEL-HW
6 setup-xorg-base
13 adduser -g "willi book" willi
14 adduser willi wheel
15 apk add doas
17 apk add nano
18 nano /etc/doas.d/doas.conf
19 adduser willi video
20 adduser willi input
24 apk add linux-firmware-radeon
25 echo >> radeon /etc/modules
26 echo >> fbcon /etc/modules
27 apk add mkinitfs
28 nano /etc/mkinitfs/mkinitfs.conf
29 mkinitfs
30 reboot
31 apk add xf86-video-ati
34 apk add kbd
37 apk add xf86-input-evdev
39 apk add xf86-input-libinput
40 setup-desktop
41 reboot
46 apk add gedit
47 history
49 history >history.txt
https://wiki.alpinelinux.org/wiki/Main_Page
Linux audio recording guide (PulseAudio or PipeWire)
This article explains how to record an audio stream on a Linux system running either PulseAudio or PipeWire. (The commands below are all PulseAudio commands, but they should work on a PipeWire system thanks to its PulseAudio compatibility.)
You can record both input streams (microphones) and output streams (whatever you are hearing in your headphones). However, each stream goes to a separate file. If you want to record a conversation, record both streams and mix them afterwards in an audio editor/DAW.
First, find out the PulseAudio name of the stream you want to record.
If you want to record a microphone, run
pactl --format=json list sources | jq '.[] | select(.monitor_source == "") | {name: .name, desc: .description}'Here is an example output:
{
"name": "alsa_input.pci-0000_06_00.6.analog-stereo",
"desc": "Family 17h/19h HD Audio Controller Analog Stereo"
}
{
"name": "alsa_input.usb-Audient_EVO4-00.analog-surround-40",
"desc": "EVO4 Analog Surround 4.0"
}The "name" component is what you need; the description is just there to help you figure out which stream is the right one.
If you want to record an output (e.g. a person you’re talking to), similarly run
pactl --format=json list sources | jq '.[] | select(.monitor_source != "") | {name: .name, desc: .description}'Once you know the name of the stream you want to record, run
parecord --channels=1 --file-format=flac --device $STREAM_NAME filename.flacWhen you are done recording, terminate the process by pressing Ctrl-C.
--channels=1 forces your recording to mono, which is usually what you want.
To see the list of supported file formats, run
parecord --list-file-formatsIf you try to record a generic output, such as alsa_output.pci-0000_06_00.6.analog-stereo.monitor, you might also capture some unwanted output from other applications or notification sounds. To make sure only a specific application is recorded, here’s what you can do:
- Create a fresh sink that will send its input to headphones, but to which no application is connected by default.
- Direct the sound from the specific applications you want to record into this new sink.
- Record the output of the new sink.
Find out the name of your output device by running
pactl --format=json list sinks | jq '.[] | {name: .name, desc: .description}'In my case, it says
{
"name": "alsa_output.pci-0000_06_00.6.analog-stereo",
"desc": "Family 17h/19h HD Audio Controller Analog Stereo"
}
{
"name": "alsa_output.usb-Audient_EVO4-00.analog-surround-40",
"desc": "EVO4 Analog Surround 4.0"
}Let’s say my headphones are connected to EVO 4. Then I would run:
OUTPUT_NAME=alsa_output.usb-Audient_EVO4-00.analog-surround-40
pactl load-module module-combine-sink sink_name=recording sink_properties=device.description=Recording slaves=$OUTPUT_NAME
parecord --channels=1 --file-format=flac --device recording.monitor filename.flacNow, redirect the sound to the Recording sink:
- Run the
pavucontrolcommand (a graphical window will appear) and go to the “Playback” tab. - Start the application you’d like to record.
- The application should appear in
pavucontrol. If it doesn’t, make sure the application produces some sound. Unfortunately, until the application tries to play something, PulseAudio/PipeWire cannot “see” it. - Choose the
Recordingsink for the application as shown on the screenshot:

How to Install NVIDIA Drivers on Debian
In this tutorial, we will guide you through the NVIDIA driver installation process on Debian.

Prerequisites
- A system running Debian (the guide uses Debian 12 Bookworm).
- An account with sudo privileges.
- Access to the terminal window.
- (Optional) Access to a web browser.
Note: If you are working on an older machine, use the nvidia-detect tool to determine the appropriate driver version. Install it with sudo apt nvidia-detect and run nvidia-detect as a command to determine the appropriate driver version.
Install NVIDIA Drivers Via Debian Repository
The first method focuses on installing NVIDIA drivers from the Debian repositories. NVIDIA recommends using this method for Linux systems due to improved interactions.
Follow the steps below to install the drivers via the Debian repository.
Step 1: Enable Non-Free Repositories
Adjust the APT sources list to include non-free repositories before installing. To enable them, do the following in the terminal:
1. Open the APT sources list file using a text editor:
sudo nano /etc/apt/sources.list
2. Add the contrib and non-free repositories to the sources list links. For example:
deb http://deb.debian.org/debian/ bullseye main contrib non-free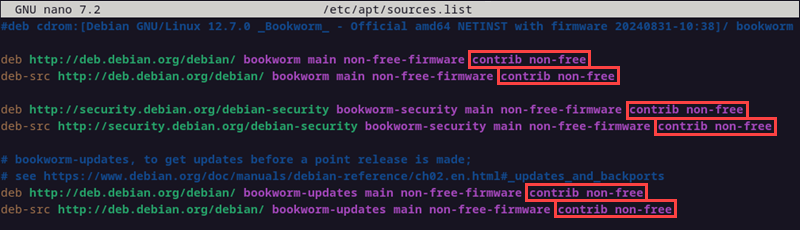
Enabling the repositories gives access to proprietary drivers that are not open source, including NVIDIA drivers.
3. Press Ctrl+X, Y, and Enter to save changes and exit the configuration file.
4. Update the system repository index:
sudo apt updateThe update ensures the newest data from the added repositories is available.
Step 2: Install NVIDIA Drivers
To install the driver, see the steps below:
1. Run the following apt command to install the driver:
sudo apt install nvidia-driver
The command also installs necessary dependencies. Press y and Enter to confirm the installation.
2. If the system prompts that there is a conflicting driver, a restart after the installation resolves the issue.
Press Enter to confirm and continue the installation.
3. Once the installation completes, reboot your system with:
sudo rebootThe driver loads immediately after reboot.
Install NVIDIA Drivers Via Official nvidia.com Package
This method lets you manually download and install an NVIDIA driver package from the official website.
Step 1: Download Drivers
To download the NVIDIA driver installer, do the following:
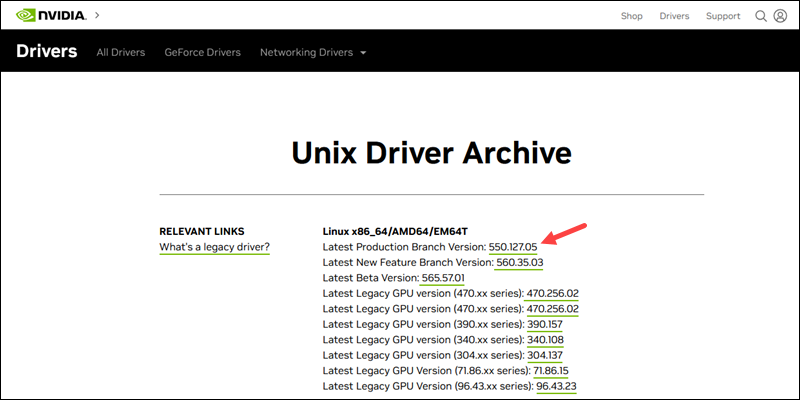
Click the version number to access the downloads page.
2. Click the Download button and save the file.
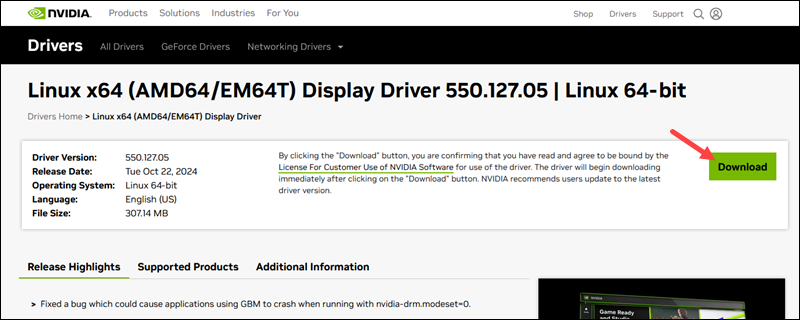
The file is in the ~/[username]/Downloads directory of the currently logged-in user.
Step 2: Install Driver Prerequisites
Install the driver prerequisites. Run the following in the terminal:
sudo apt -y install linux-headers-$(uname -r) build-essential libglvnd-dev pkg-config
The packages ensure that NVIDIA drivers compile successfully.
Step 3: Disable Default Drivers
Disable the default nouveau GPU driver:
1. Create and open a new configuration file using nano:
sudo nano /etc/modprobe.d/blacklist-nouveau.confThe configuration file is in the kernel module loading directory.
2. Add the following lines to the file:
blacklist nouveau
options nouveau modeset=0
The file instructs the system to prevent the Nouveau kernel module from loading and disables the open-source driver.
3. Save the changes and exit. Press Ctrl+X, Y, and Enter.
4. Update the kernel initramfs with:
sudo update-initramfs -u
The rebuild takes several moments to complete. It ensures that essential drivers load and the root filesystem mounts early in the boot process. It ensures the changes apply after rebooting.
Step 4: Reboot to Multi-User Login
Since the default GPU drivers are now disabled, switching to a text-based interface lets you install NVIDIA drivers without using the GUI.
1. Enable the text-based multi-user login prompt:
sudo systemctl set-default multi-user.target
The command creates a symlink and outputs the result.
2. Reboot the system with:
systemctl rebootThe system restarts into the terminal without a GUI.
Step 5: Install Nvidia Drivers
Once the system restarts, do the following:
1. Log in as root.

cd /home/[username]/Downloads3. Install the Nvidia drivers using the package you downloaded:
bash ./[driver file name]For example:
bash ./NVIDIA-Linux-x86_64-550.127.05.run
3. If prompted, choose the following options during the install process:
- The CC version check failed: Ignore CC version check.
- Install NVIDIA's 32-bit compatibility libraries: Yes.
- Rebuild initramfs: Yes.
- An incomplete installation of libglvnd was found. Do you want to install a full copy of libglvnd? This will overwrite any existing libglvnd libraries: Install and overwrite existing filesort installation.
- Would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver will be used when you restart X? Any pre-existing X configuration file will be backed up: Yes.
4. Wait for the process to complete until it shows the installation was successful.
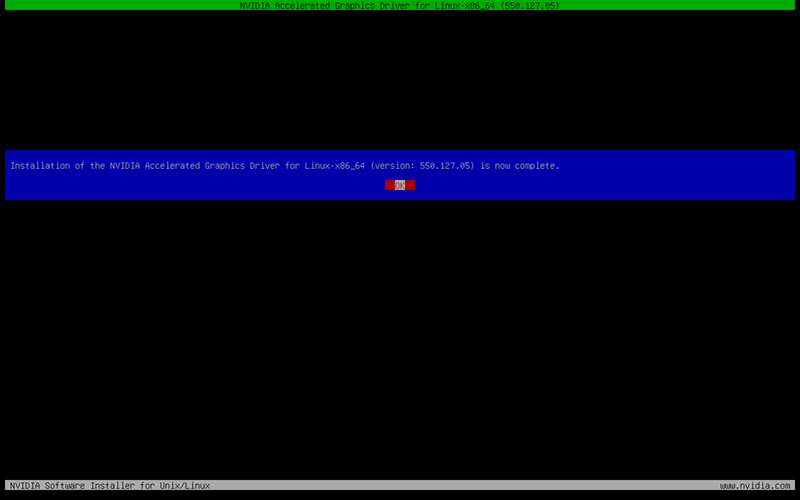
Press Enter to confirm and exit the installer. The prompt returns to the terminal.
Step 6: Enable GUI
Re-enable the GUI to complete the process and start up the new drivers:
1. Enable the GUI login prompt with:
systemctl set-default graphical.target
2. Reboot your system to finish the installation:
rebootThe system starts up using the new driver.
Conclusion
This guide showed how to install the newest NVIDIA GPU drivers on Debian 12 using two different methods.
20 häufige Linux IPTables Firewall Regeln
Lernen Sie die wichtigsten IPTables Regeln kennen welche oft verwendet werden um ihren Server abzusichern, Ports weiterzuleiten oder den Traffic an mehrere Server aufzuteilen wie einem Load Balancer.
In diesem Beispielen verwenden wir ETH0 als Netzwerk Interface, eine abwandlung der Befehle ist ganz einfach durch austauschen des Interfaces möglich, wenn Sie z.B. virtuelle Interface haben wir VENET0:0 oder dergleichen.
Um herauszufinden welchen Netzwerk Interface namen Sie haben verwenden Sie einfach:
ifconfig
1. Auflistung der Firewall Regeln
Um die derzeitigen Filterregeln auflisten zu können benötigen wir die List Option. Dann sehen Sie ob Regeln aktiv sind oder ob keine Regeln vorhanden sind.
iptables -L
2. Löschen einer existierenden Regel
Bevor wir neue Regel erstellen, bereinigen wir zuerst einmal alle vorherigen Regeln damit wir von vorne Beginnen. Um die derzeit gültigen Regeln alle zu löschen benötigen wir einen "flush". Dies geschieht entwedert mit -F oder --flush
iptables -F (oder) iptables --flush
3. Setzen einer Standart Regeln
Standartmäßig wenn keine Einstellungen und Regeln gesetzt sind, wird jede Verbindung zum System auf "Accept" (Erlaubt) gestellt. Um die Verbindungen zu schließen können wir anstellen von ACCEPT die Regeln auf DROP (Überspringen) für den Input, Output und Forward.
iptables -P INPUT DROP iptables -P FORWARD DROP iptables -P OUTPUT DROP
Wenn wir die Input und Output Regel standardmäßig auf Drop setzen, müssen Sie für jede weitere Regel sowohl Input als auch Output per Accept wieder freigeben, je nach ihren Anforderungen.
In den Beispielen unterhalb haben wir Regeln sowohl für den Input als auch den Output welchen wir freigeben können. Es hängt von ihren Individuellen Einstellungen ab was für Sie sinnvoll ist.
4. Blockieren einer Spezifischen IP Adresse
Um eine einzelne IP Adresse z.B. für den Input Traffic zu sperren können Sie auch speziell eine Regel setzen. Je nachdem ob Sie eine Allgemeine Drop Regel nutzen oder nicht. Ersetzen Sie hierfür einfach x.x.x.x durch die IP Adresse welche gesperrt werden soll.
iptables -A INPUT -s "x.x.x.x" -j DROP
Diese Regel macht sinn wenn Sie Auffälligkeiten im System bemerken welche von der gesperrten IP Adresse kommen und Sie diese Temporär blockieren wollen.
Sie können die IP Adresse auch spezifisch auf einem Interface blockieren oder rein auf den Traffic via TCP.
iptables -A INPUT -i eth0 -s "x.x.x.x" -j DROP iptables -A INPUT -i eth0 -p tcp -s "x.x.x.x" -j DROP
5. Erlauben sie SSH Zugriff auf ihrem System
Um SSH freizuschalten können wird den Port 22 für Input und Output freigeben. Natürlich können Sie auch SSH auf einen anderen Port laufen lassen. Hierfür dann entsprechen die 22 editieren.
iptables -A INPUT -i eth0 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
5. Erlauben von SSH nur auf einem spezifischen Netzwerk
Die folgende Regel erlaubt den SSH Zugriff nur von dem einem internen Netzwerk mit den IP Adresse beginnen mit 192.168.100.x.
iptables -A INPUT -i eth0 -p tcp -s 192.168.100.0/24 --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
In diesem Beispiel nutzen wir ein 24er Subnetz. Sie können natürlich auch die volle Subnet mask nutzen.
6. Erlauben von HTTP und HTTPS verbindungen
Webserver nutzen HTTP (Port 80) und HTTPS (Port 443) für das anzeigen von Webseiten, die folgende Regel erlaubt den Zugriff auf ihren Webserver via HTTP von Extern.
iptables -A INPUT -i eth0 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT
Nun die selbe Regel für den HTTPS Port 443 um auch sicheren Webseiten anzeigen zu können.
iptables -A INPUT -i eth0 -p tcp --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 443 -m state --state ESTABLISHED -j ACCEPT
7. Mehrere Regeln zusammenführen in eine Regel
Wenn Sie Traffic von ausserhalb auf mehrere Ports erlauben wollen, macht es oft sinn dies in eine einzelne Regel zu verpacken, anstatt für jeden Port eine eigene Regel zu schreiben. Hier ersparen wir uns eine unzählige Anzahl an widerholungen.
Im folgenden Beispiel erlauben wir den Traffic von SSH (22), HTTP (80) and HTTPS (443).
iptables -A INPUT -i eth0 -p tcp -m multiport --dports 22,80,443 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m multiport --sports 22,80,443 -m state --state ESTABLISHED -j ACCEPT
8. Load Balance eingehenden Web Traffic
Es ist möglich den eingehenden Traffic aufzuteilen auf mehrere IP Adressen. Umgangssprachlich auch ein sogenannter Load Balancer ermöglicht solche aufgaben.
Um den Traffic aufzuteilen benötigen wir in IPTables die nth Erweiterung. Das folgende Beispiel zeit wie HTTPS traffic auf drei unterschiedliche IP Adressen aufgeteilt wird. Für jedes 3te Paket das ankommt wird die nächste IP herangezogen welche den counter bei 0 halt.
iptables -A PREROUTING -i eth0 -p tcp --dport 443 -m state --state NEW -m nth --counter 0 --every 3 --packet 0 -j DNAT --to-destination 192.168.1.101:443 iptables -A PREROUTING -i eth0 -p tcp --dport 443 -m state --state NEW -m nth --counter 0 --every 3 --packet 1 -j DNAT --to-destination 192.168.1.102:443 iptables -A PREROUTING -i eth0 -p tcp --dport 443 -m state --state NEW -m nth --counter 0 --every 3 --packet 2 -j DNAT --to-destination 192.168.1.103:443
9. Erlaube Pingen von Aussen nach Innen
Die folgende Regel erlaubt Benutzern von ausserhalb die Seerver zu Pingen und erhalten im Output auf die Antwort.
iptables -A INPUT -p icmp --icmp-type echo-request -j ACCEPT iptables -A OUTPUT -p icmp --icmp-type echo-reply -j ACCEPT
10. Erlaube Loopback zugriff
Die eigene 127.0.0.1 Loopback Adresse können wir ebenfalls freischalten. Das ist dann sinnvoll wenn z.B. ein SQL Server auf dem Localhost läuft und mit 127.0.0.1 angesprochen werden soll.
iptables -A INPUT -i lo -j ACCEPT iptables -A OUTPUT -o lo -j ACCEPT
11. Internes Netzwerk zu Externes Netzwerk
Auf einem Server mit zwei Netzwerk Karten ist es möglich wenn eine Netzwerkkarte auf dem Internet Netzwerk hängt und die andere auf dem externen Netzwerk diese Weiterzuleiten (Forwarden).
In diesem Beispiel ist eth1 an das externe Netzwerk (internet) angebungen, und eth0 an das interne Netzwerk (192.168.0.x).
iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT
12. Erlauben von outbound DNS
Die folgende Regel erlaubt ausgehende DNS verbindungen.
iptables -A OUTPUT -p udp -o eth0 --dport 53 -j ACCEPT iptables -A INPUT -p udp -i eth0 --sport 53 -j ACCEPT
13. Rsync von einem spezifischen Netzwerk erlauben
Die folgende Regel erlaubt rsync Verbindungen von deinem fix definierten Netzwerk.
iptables -A INPUT -i eth0 -p tcp -s 192.168.10.0/24 --dport 873 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 873 -m state --state ESTABLISHED -j ACCEPT
14. MySQL Verbindungen nur von einem spezifischen Netzwerk erlauben.
Wenn Sie einen MySQL Server laufen haben, wollen Sie üblicherweise keine direkte Verbindung von ausserhalb erlauben. Den die Verbindungen direkt zum Server erfolgen in der Regel unverschlüsselt und Hacker könnten so einfach an wichtigen Informationen gelangen.
Es ist daher anzuraten das Sie nur direkte verbindungen zu lassen von dem Internen Netzwerk. DBA und Entwickler können den Umweg eines Jumpservers nutzen. Im folgenden Beispiel öffnen wir den Port für MySQL 3306 nur für interne Verbindungen aus dem eignen LAN.
iptables -A INPUT -i eth0 -p tcp -s 192.168.100.0/24 --dport 3306 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 3306 -m state --state ESTABLISHED -j ACCEPT
15. Erlauben von Sendmail oder Postfix Traffic
Die folgende Regel erlaubt den Datenverkehr auf Port 25 für Mailserver wie z.B. Sendmail oder Postfix.
iptables -A INPUT -i eth0 -p tcp --dport 25 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 25 -m state --state ESTABLISHED -j ACCEPT
16. Erlauben von IMAP und IMAPS Verbindungen
Die folgende Regel erlaubt den Datenverkehr auf Port 143 und 993 für IMAP (143) und IMAPS (993) Verbindungen.
iptables -A INPUT -i eth0 -p tcp --dport 143 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 143 -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --dport 993 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 993 -m state --state ESTABLISHED -j ACCEPT
17. Erlauben von POP3 und POP3S Verbindungen
Die folgende Regel erlaubt den Datenverkehr auf Port 110 und 995 für POP3 (110) und POP3S (995) Verbindungen.
iptables -A INPUT -i eth0 -p tcp --dport 110 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --sport 110 -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --dport 995 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp --sport 995 -m state --state ESTABLISHED -j ACCEPT
18. Vorbeugen einer DoS Attacke
Die folgende Regel hilft ihnen einen Denial of Service (DoS) auf ihren Webserver abzufangen.
iptables -A INPUT -p tcp --dport 80 -m limit --limit 25/minute --limit-burst 100 -j ACCEPT
In dem Beispiel darüber geschieht folgendes:
19. Port Forwarding / Port Weiterleitung
Das folgende Beispiel zeigt wie man den Traffic auf einen anderen Port am selben Server umleiten kann. So ist z.B. dann eine SSH Verbindung über den Port 422 erreichbar obwohl er in Wirklichkeit auf Port 22 lauscht.
iptables -t nat -A PREROUTING -p tcp -d 192.168.10.2 --dport 422 -j DNAT --to 192.168.10.2:22
Natürlich müssen Sie nun auch den Port 422 freigeben um auf diesen Port zugreifen zu können. Eine Freigabe des Ports 22 ist dann nicht mehr Notwendig von extern.
iptables -A INPUT -i eth0 -p tcp --dport 422 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp --sport 422 -m state --state ESTABLISHED -j ACCEPT
20. Protokollieren / Loggen von Paketen welche übersprungen wurden. (Dropped Packets)
Diese Regel sollte ganz zum Schluss kommen um die übersprungenen Pakete zu Loggen / Protokollieren.
Zuerst erstellen wir eine neue Regel die "LOGGING" heißt.
iptables -N LOGGING
Als nächstes stellen wir sicher das alle Verbindungen die LOGGING Regeln durchlaufen um Sie später nach übersprungenen Paketen zu durchsuchen.
iptables -A INPUT -j LOGGING
Nun spezifizieren wir die Pakete mit einem log-prefix auf dem log-level 7 und filtern diese.
iptables -A LOGGING -m limit --limit 2/min -j LOG --log-prefix "IPTables Packet Dropped: " --log-level 7
Zu guter letzt werden die IPs dieser Pakete nun gesperrt.
iptables -A LOGGING -j DROP
Paperless - Readme
Features
- Organize and index your scanned documents with tags, correspondents, types, and more.
- Your data is stored locally on your server and is never transmitted or shared in any way.
- Performs OCR on your documents, adding searchable and selectable text, even to documents scanned with only images.
- Utilizes the open-source Tesseract engine to recognize more than 100 languages.
- Documents are saved as PDF/A format which is designed for long term storage, alongside the unaltered originals.
- Uses machine-learning to automatically add tags, correspondents and document types to your documents.
- Supports PDF documents, images, plain text files, Office documents (Word, Excel, Powerpoint, and LibreOffice equivalents)1 and more.
- Paperless stores your documents plain on disk. Filenames and folders are managed by paperless and their format can be configured freely with different configurations assigned to different documents.
- Beautiful, modern web application that features:
- Customizable dashboard with statistics.
- Filtering by tags, correspondents, types, and more.
- Bulk editing of tags, correspondents, types and more.
- Drag-and-drop uploading of documents throughout the app.
- Customizable views can be saved and displayed on the dashboard and / or sidebar.
- Support for custom fields of various data types.
- Shareable public links with optional expiration.
- Full text search helps you find what you need:
- Auto completion suggests relevant words from your documents.
- Results are sorted by relevance to your search query.
- Highlighting shows you which parts of the document matched the query.
- Searching for similar documents ("More like this")
- Email processing1: import documents from your email accounts:
- Configure multiple accounts and rules for each account.
- After processing, paperless can perform actions on the messages such as marking as read, deleting and more.
- A built-in robust multi-user permissions system that supports 'global' permissions as well as per document or object.
- A powerful workflow system that gives you even more control.
- Optimized for multi core systems: Paperless-ngx consumes multiple documents in parallel.
- The integrated sanity checker makes sure that your document archive is in good health.
Paperless, a history
Paperless-ngx is the official successor to the original Paperless & Paperless-ng projects and is designed to distribute the responsibility of advancing and supporting the project among a team of people. Consider joining us!
Further discussion of the transition between these projects can be found at ng#1599 and ng#1632.
Screenshots
Paperless-ngx aims to be as nice to use as it is useful. Check out some screenshots below.
The document list provides three different styles to browse your documents.

Of course, Paperless-ngx also supports dark mode:
Side-by-side editing of documents.


Tag, correspondent, document type and storage path editing.


{: style="width:21%; margin-left: 4%; float: left"}


Mobile devices are supported.


Support
Community support is available via GitHub Discussions and the Matrix chat room.
Feature Requests
Feature requests can be submitted via GitHub Discussions where you can search for existing ideas, add your own and vote for the ones you care about.
Bugs
For bugs please open an issue or start a discussion if you have questions.
Contributing
People interested in continuing the work on paperless-ngx are encouraged to reach out on GitHub or the Matrix chat room. If you would like to contribute to the project on an ongoing basis there are multiple teams (frontend, ci/cd, etc) that could use your help so please reach out!
Translation
Paperless-ngx is available in many languages that are coordinated on Crowdin. If you want to help out by translating paperless-ngx into your language, please head over to the Paperless-ngx project at Crowdin, and thank you!
Scanners & Software
Paperless-ngx is compatible with many different scanners and scanning tools. A user-maintained list of scanners and other software is available on the wiki.
Footnotes
-
Office document and email consumption support is optional and provided by Apache Tika (see configuration) ↩ ↩2
Debian Multimedia Repo
Programme wie avidemux, kodi, vlc oder obs sind nicht immer (oder nicht in aktueller Version) im Standard-Repository von Debian. Hier eine kleine Anleitung um das Repo von deb-multimedia.org einzubinden.
Als erstes laden fügen wir uns den benötigten GPG-Key hinzu:
wget http://www.deb-multimedia.org/pool/main/d/deb-multimedia-keyring/deb-multimedia-keyring_2016.8.1_all.deb sudo dpkg -i deb-multimedia-keyring_2016.8.1_all.deb
Jetzt noch das Repository (in diesem Fall für Debian bullseye):
echo "deb https://www.deb-multimedia.org bullseye main non-free" | sudo tee /etc/apt/sources.list.d/deb-multimedia.list
Linux Page Cache
Der Page Cache unter Linux beschleunigt zahlreiche Lese-Zugriffe von Dateien. Dies geschieht, indem Linux Daten beim erstmaligen Lesen von oder Schreiben auf Datenträgern wie Festplatten zusätzlich in ungenutzten Bereichen des Arbeitsspeichers cacht. Werden diese Daten später erneut gelesen, können diese schnell aus dem Arbeitsspeicher gelesen werden. Dieser Artikel liefert wertvolle Hintergrundinformationen zum Page Cache.
Page Cache oder Buffer Cache
Oft wird für den Page Cache noch der Begriff Buffer Cache verwendet. Bei Linux Kerneln bis Version 2.2 gab es sowohl einen Page Cache, als auch einen Buffer Cache. Mit Kernel 2.4 wurden diese beiden Caches vereint. Heute gibt es nur noch einen Cache, den Page Cache.[1]
Funktionsweise
Auslastung
Unter Linux gibt das Kommando free -m in der Spalte cached an, wieviel MB des Arbeitsspeichers momentan für den Page Cache verwendet werden:
[root@testserver ~]# free -m
total used free shared buffers cached
Mem: 15976 15195 781 0 167 9153
-/+ buffers/cache: 5874 10102
Swap: 2000 0 1999
[root@testserver ~]#
Schreiben
Wenn Daten geschrieben werden, kommen diese zuerst in den Page Cache und werden dort als Dirty Pages verwaltet. Dirty deshalb, weil diese Daten zwar im Page Cache liegen, aber erst auf das darunterliegende Speichergerät geschrieben werden müssen. Der Inhalt dieser Dirty Pages wird regelmäßig (bzw. auch beim Aufruf von Systemcalls wie sync oder fsync) auf das darunterliegende Speichergerät weitergegeben. Dies kann in letzter Instanz etwa ein RAID-Controller oder direkt eine Festplatte sein.
Das folgende Beispiel zeigt die Erstellung einer 10 MByte großen Datei, die zuerst in den Page Cache geschrieben wird. Der Umfang der Dirty Pages steigt dadurch, bis diese in diesem Fall manuell per sync Kommando auf die darunterliegende SSD geschrieben werden:
wfischer@pc:~$ dd if=/dev/zero of=testfile.txt bs=1M count=10 10+0 records in 10+0 records out 10485760 bytes (10 MB) copied, 0,0121043 s, 866 MB/s wfischer@pc:~$ cat /proc/meminfo | grep Dirty Dirty: 10260 kB wfischer@pc:~$ sync wfischer@pc:~$ cat /proc/meminfo | grep Dirty Dirty: 0 kB
bis Kernel 2.6.31: pdflush
Bis inklusive Linux Kernel 2.6.31 sorgten die pdflush Threads dafür, dass Dirty Pages regelmäßig auf die darunterliegenden Speichergeräte geschrieben wurden.
ab Kernel 2.6.32: Per-backing-device based writeback
Da pdflush einige Performance-Nachteile hatte, entwickelte Jens Axboe für den Linux Kernel 2.6.32 einen neuen effektiveren writeback Mechanismus.[2]
Dabei gibt es nun Threads für jedes Gerät, wie folgendes Beispiel eines Rechners mit einer SSD (/dev/sda) und einer Festplatte (/dev/sdb) zeigt:
root@pc:~# ls -l /dev/sda brw-rw---- 1 root disk 8, 0 2011-09-01 10:36 /dev/sda root@pc:~# ls -l /dev/sdb brw-rw---- 1 root disk 8, 16 2011-09-01 10:36 /dev/sdb root@pc:~# ps -eaf | grep -i flush root 935 2 0 10:36 ? 00:00:00 [flush-8:0] root 936 2 0 10:36 ? 00:00:00 [flush-8:16]
Lesen
Nicht nur beim Schreiben, auch beim Lesen von Dateien kommen Dateiblöcke in den Page Cache. Wenn Sie z.B. eine 100 MB Datei zweimal hintereinander lesen, so wird der zweite Zugriff schneller sein, da die Dateiblöcke direkt aus dem Page Cache im Arbeitsspeicher kommen und nicht mehr erneut von der Festplatte gelesen werden müssen. Das folgende Beispiel zeigt, dass nach der Wiedergabe eines gut 200 MB großen Videos die Größe des Page Caches angestiegen ist:
user@adminpc:~$ free -m
total used free shared buffers cached
Mem: 3884 1812 2071 0 60 1328
-/+ buffers/cache: 424 3459
Swap: 1956 0 1956
user@adminpc:~$ vlc video.avi
[...]
user@adminpc:~$ free -m
total used free shared buffers cached
Mem: 3884 2056 1827 0 60 1566
-/+ buffers/cache: 429 3454
Swap: 1956 0 1956
user@adminpc:~$
Benötigt Linux mehr Arbeitsspeicher für normale Applikationen als aktuell frei ist, werden bereits länger nicht mehr genutzte Bereiche des Page Caches automatisch gelöscht.
Page Cache optimieren
Das automatische Caching von Dateiblöcken im Page Cache ist meistens sehr vorteilhaft. Manche Daten (etwa Logfiles oder MySQL-Dumps) werden aber oft nach dem Schreiben nicht mehr benötigt. Solche Dateiblöcke belegen also oft unnötig Platz im Page Cache. Andere Dateiblöcke, deren Caching mehr Vorteile bringen würde, fliegen durch die neuen Logfiles oder MySQL aus dem Page Cache hinaus.[3]
Bei Logdateien hilft Ihnen hier etwa ein regelmäßiges Logrotate mit gzip Kompromierung. Wenn eine Logdatei mit beispielsweise 500 MB durch logrotate und gzip auf 10 MB komprimiert wird, wird die ursprüngliche Logdatei und somit auch deren Cache ungültig. 490 MB im Page Cache werden dadurch frei. Die Gefahr, dass eine kontinuierlich wachsenende Logdatei dadurch sinnvollere Dateiblöcke aus dem Page Cache "hinausschiebt" sinkt somit.
Es macht also durchaus Sinn, wenn manche Anwendungen bestimmte Dateien/Dateiblöcke gar nicht cachen würden. Für rsync gibt es dazu auch bereits einen Patch.[4]
Rechte im Dateisystem mehr als nur r,w,x
Erfahren Sie, wie Sie einfacher Verzeichnisstrukturen für Mitarbeiter bereitstellen und diese mit den benötigten Rechten und ACLs versehen können.
Stefan Kania 08. September 2015

Jeder der schon mal mit Linux auf der Kommandozeile gearbeitet hat und dort administrativ tätig war, kennt diese drei Buchstaben: "rwx" und das pro Eintrag im Dateisystem dreimal. Die Dateisystemberechtigungen! Aber was verbirgt sich noch hinter dem Begriff "Dateisystemberechtigungen"? Weit mehr als nur die drei Berechtigungen "read", "write" und "execute". Mit diesem Artikel werde ich weitere Facetten der Dateisystemberechtigungen wie "special Bits", "Access Control Lists" und "erweiterte Attribute" ansprechen.
Immer wieder höre ich in den Grundlagenseminaren zu Linux von Teilnehmern, dass man mit den drei einfachen Rechten "read", "write" und "execute" nicht viel anfangen kann. Dass komplexe Abbildungen von Zugriffsrechten unter Windows viel besser seien. Wo reicht es denn heute noch aus, dass man nur einem Benutzer und einer Gruppe Rechte an einem Verzeichnis oder einer Datei geben kann? Aber nicht nur Einsteiger, auch so mancher Admin stößt immer wieder an seine Grenzen.
Ich will in diesem Artikel nicht nur erklären, wie die Rechte funktionieren, was man mit den Rechten alles machen kann, sondern ich will auch praktische Tipps geben, die vielleicht das Leben mit den Dateisystemrechten etwas angenehmer machen können. Neben den bekannten Dateisystemrechten gehören auch noch die "special Bits", die "Access Contol Lists (ACL)" und die erweiterten Attribute in ein gut geplantes Berechtigungskonzept. Auch diese Themen werde ich in diesem Artikel ansprechen.
Die altbekannten Buchstaben "r","w","x"
Im Schnelldurchlauf will ich hier noch mal die Rechte "read", "write" und "execute" erklären, wobei ich dabei auch die unterschiedlichen Bedeutungen der Rechte an Dateien und Verzeichnissen erläutern werde:
- read
Das "read"-Recht an einer Datei bedeutet, die Datei kann zum Lesen geöffnet werden. Der Anwender der dieses Recht hat, kann den Inhalt lesen, aber nicht verändern. Das "read"-Recht an einem Verzeichnis erlaubt es, dass ein Anwender sich den Inhalt des Verzeichnisses mit "ls" anzeigen lassen kann. - write
Das "write"-Recht an einer Datei erlaubt es dem Anwender, den Inhalt einer Datei zu verändern. Er hat dadurch nicht das Recht, den Dateinamen zu ändern oder gar eine Datei zu löschen. Erst wenn ein Anwender das "write"-Recht an einem Verzeichnis hat, kann er die Einträge im Verzeichnis löschen, umbenennen und neue Einträge erstellen. Die Vergabe des "write"-Rechts an einem Verzeichnis sollte daher immer gut überlegt sein. Das Recht erlaubt es einem Anwender, alle Einträge in dem Verzeichnis zu löschen, auch wenn er an den Einträgen selbst keine Rechte hat. In allen heutigen Unix/Linux-Systemen muss der Anwender aber alle drei Rechte besitzen, um Einträge löschen, umbenennen oder erstellen zu können. - execute
Das "execute"-Recht erlaubt es einem Anwender, eine Datei auszuführen. Auf Binärdateien und Shell-Skripte muss immer das "execute"-Recht gesetzt sein, damit ein Anwender das Programm oder Shell-Skript ausführen kann. Hat ein Anwender das "execute"-Recht an einem Verzeichnis, kann er mit dem Kommando "cd" in das Verzeichnis wechseln.
user, group, other
Neben den Rechten selbst gibt es dann noch die Zuordnung der Rechte. Es gibt drei Berechtigungszuordnungen: Da wäre als erstes der Besitzer einer Datei (user), dann die besitzende Gruppe (group) und abschließend noch der Rest der Welt (other). Jeder dieser Berechtigungszuordnungen können die Rechte "read", "write" und "execute" zugeordnet werden. Ein Anwender kann aber immer nur die Rechte über eine der Berechtigungszuordnungen erhalten. Er ist also entweder der Besitzer einer Datei, dann erhält er die Rechte von "user", oder er ist Mitglied der besitzenden Gruppe, dann erhält er die Rechte von "group". Wenn er weder Besitzer noch Mitglied der besitzenden Gruppe ist, erhält er immer die Rechte von "other". Sie sehen schon, Rechte über "other" zu vergeben ist keine gute Lösung, da Sie den Zugriff auf Dateisystemeinträge nicht wirklich steuern können.
Immer alles Oktal
Systeme können nichts mit Buchstaben wie "r", "w" oder "x" anfangen, Systeme benötigen Zahlen und die am besten im Binärformat. Deshalb werden die Berechtigungen intern in Binärwerten mit drei Stellen abgebildet. Daraus entstehen dann die Oktalwerte für die Rechte wie Sie sie in der Tabelle sehen können. Egal ob für "user", "group" oder "other" – die Rechte haben dabei die folgenden Wertigkeiten:
Recht Binärwert Oktalwert -------- ------------ ---------------- read 2^2 4 write 2^1 2 execute 2^0 1
Werden also alle Rechte an eine Berechtigungszuordnung vergeben, ergibt das einen Oktalwert von "7". Maximal also "777".
Woher kommen die Rechte im Dateisystem?
Wenn Sie eine Datei oder ein Verzeichnis anlegen, haben diese Einträge bereits Berechtigungen, aber wo kommen diese Berechtigungen her? Eine Vererbung wie Sie sie von Windows her kennen gibt es unter Linux nicht. Hier ist die "umask" für die Vergabe der Berechtigungen eines neuen Eintrags im Dateisystem verantwortlich. Sie können sich die Umask mit dem gleichnamigen Kommando anzeigen lassen. Hier ein Beispiel:
stefan@stefan:~% umask 022
Die drei Stellen der Umask stehen hier für eine Berechtigungszuordnungen. Die erste Stelle für "user", die zweite für "group" und die dritte für "other". Die Umask zeigt an, welche Rechte beim Anlegen eines neuen Eintrags im Dateisystem NICHT vergeben werden. Der Besitzer erhält immer alle Rechte, die besitzenden Gruppe alles außer dem Schreibrecht, genau wie der Rest der Welt. Das bedeutet in der Standardeinstellung kann der Rest der Welt immer in alle Verzeichnisse wechseln und sich den Inhalt aller Dateien anzeigen lassen. Jeder Anwender kann über die Kommandozeile die Einstellung der Umask mit dem Kommando "umask <wert>" selbst anpassen. Später in diesem Artikel werde ich noch auf die Planung eines Berechtigungskonzeptes eingehen, dabei werde ich zeigen, wie man die Umask auch systemweit setzen können. Doch sehen wir uns einmal je einen neuen Eintrag für eine Datei und ein Verzeichnis an und vergleichen dieses mit der gesetzten Umask:
stefan@stefan:~% ls -l insgesamt 4 -rw-r--r-- 1 stefan users 0 Aug 4 11:34 datei1 drwxr-xr-x 2 stefan users 4096 Aug 4 11:34 verzeichnis1
Hier sieht man, dass die Berechtigungen am Verzeichnis mit der Umask übereinstimmen. Der Gruppe und dem Rest der Welt wurde das Schreibrecht nicht vergeben. Der Besitzer hat alle Rechte. Aber was ist mit der Datei? Da fehlt bei allen drei Berechtigungszuordnungen das Execute-Recht. Das ist auch korrekt so! Denn das Betriebssystem überprüft beim Anlegen einer neuen Datei, ob es überhaupt Sinn macht, das Execute-Rechte an der Datei zu setzen. Bei allen nicht-binär-Dateien macht das Setzen des Execute-Rechts auch keinen Sinn, also setzt das System das Recht auch nicht. Nur wenn Sie einen Quellcode kompilieren und dabei eine ausführbare Datei entsteht, dann wird auch das Execute-Recht entsprechend der Umask gesetzt.
Wie werden Rechte gesetzt?
Nach dem Sie jetzt eine Einführung zu den Rechten erhalten haben, will ich jetzt erklären, wie die Rechte gesetzt werden und wer alles Rechte setzen kann. Auch das Ändern der besitzenden Gruppe und des Besitzer will ich in diesem Abschnitt erklären.
Die Rechte an einem Eintrag können immer vom "root" und dem Besitzer einer Datei geändert werden. Zum Ändern der Rechte wird das Kommando "chmod" verwendet. Das Kommando "chmod" kann dabei auf zwei verschiedene Arten angewendet werden: Einmal gibt es die relative Vergabe der Berechtigungen, bei der immer die derzeitige Berechtigung geändert wird. Dann gibt es noch die absolute Vergabe der Berechtigungen, bei der der komplette Satz an Berechtigungen für alle Berechtigungszuordnungen neu erstellt wird.
Relative Vergabe der Rechte im Dateisystem
Bei der relativen Vergabe der Berechtigungen können Sie jedes einzelne Recht für sich vergeben. Hier sehen Sie einige Beispiele:
stefan@stefan:~% chmod u+x datei1 stefan@stefan:~% ls -l datei1 -rwxr--r-- 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod g-r,o-r datei1 stefan@stefan:~% ls -l datei1 -rwx------ 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod a+r datei1 stefan@stefan:~% ls -l datei1 -rwxr--r-- 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod a+rx datei1 stefan@stefan:~% ls -l datei1 -rwxr-xr-x 1 stefan users 0 Aug 4 11:34 datei1
Wie Sie an den Beispielen sehen, können Sie jedes Recht einzeln setzen. Wenn Sie ein Recht zum Beispiel mit "chmod u+x datei1" ändern wollen, aber der Besitzer bereits das Execute-Recht an der Datei hat, ändert sich nichts. Auch sehen Sie in den Beispielen, dass Sie mit der Option "a+r" oder "a-r" ein oder mehrere Rechte für alle Berechtigungszuordnungen gleichzeitig ändern können.
Absolute Vergabe der Rechte im Dateisystem
Dabei gehen Sie ganz anders vor. Sie überlegen sich, welche Rechte Sie für alle drei Berechtigungszuordnungen vergeben wollen, diese rechnen Sie dann in den entsprechenden dreistelligen Oktalwert um und vergeben dann die Rechte für den Eintrag komplett neu. Als Beispiel:
stefan@stefan:~% ls -l datei1 -rwxr-xr-x 1 stefan users 0 Aug 4 11:34 datei1 stefan@stefan:~% chmod 600 datei1 stefan@stefan:~% ls -l datei1 -rw------- 1 stefan users 0 Aug 4 11:34 datei
Hier spielt es keine Rolle, welche Rechte vorher auf dem Eintrag gesetzt waren, alle Rechte werden überschrieben.
Ändern der besitzenden Gruppe
Die besitzende Gruppe kann sowohl vom "root" als auch vom Besitzer eines Eintrags geändert werden. Wobei es für den Besitzer eine Einschränkung gibt: Er kann einen Eintrag des Dateisystems nur an Gruppen übergeben, in denen er auch Mitglied ist. Für die Änderung der besitzenden Gruppe verwenden Sie das Kommando "chgrp". Das Beispiel zeigt, wie der Gruppenbesitz geändert wird:
stefan@stefan:~% chgrp cdrom datei1 stefan@stefan:~% ls -l datei1 -rw------- 1 stefan cdrom 0 Aug 4 11:34 datei1
Ändern des Besitzers
Den Besitzer eines Eintrages im Dateisystem - gleich ob Datei oder Verzeichnis - kann nur der "root" ändern. Mit dem Kommando "chown" kann der "root" nicht nur den Besitzer ändern, sondern auch gleichzeitig die besitzenden Gruppe. Auch hierfür einige Beispiele:
root@stefan:~# chown stka datei1 root@stefan:~# ls -l datei1 -rw------- 1 stka cdrom 0 Aug 4 11:34 datei1 root@stefan:~# chown stefan:users datei1 root@stefan:~# ls -l datei1 -rw------- 1 stefan users 0 Aug 4 11:34 datei1
Wie Sie sehen, wurde dieser Vorgang als Benutzer "root" durchgeführt.
Special Bits
Bis zu diesem Punkt ist das Thema für viele von Ihnen mehr oder weniger bekannt. Jetzt kommt die erste Erweiterung der Berechtigungen. In den letzten Abschnitten habe ich immer von drei Oktalgruppen für die Berechtigungen gesprochen. Aber es gibt vier dieser Gruppen. Vor den eigentlichen Dateisystemberechtigungen steht eine vierte Gruppe bestehend aus drei Bits, die zusätzliche Rechte geben oder auch Rechte nehmen kann. Die folgende Tabelle zeigt eine Übersicht der Bits:
Rechte Binärwerte Oktalwert ------------------------------------------ SUID 2^2 4 SGID 2^1 2 Sticky Bit 2^0 1
Das SUID-Bit
Werfen wir doch einmal einen Blick auf die Rechte die an der Datei "/etc/shadow" vergeben sind:
stefan@stefan:~% ls -l /etc/shadow -rw-r----- 1 root shadow 1360 Mai 27 08:52 /etc/shadow
Da sehen Sie, dass der "root" Lese- und Schreibrecht hat und die Gruppe "shadow" nur das Leserecht. In dieser Datei befinden sich die Passwortinformationen aller Benutzer des lokalen Systems. Nur aufgrund der Rechte an der Datei sieht es so aus, als hätte ein "normaler" Benutzer keine Rechte an dieser Datei. In dieser Datei befindet sich aber das Passwort eines jeden Benutzers. Ein Benutzer kann aber sein Passwort mit dem Kommando "passwd" ändern und greift damit schreibend auf die Datei zu. Wie kann das sein? Schauen wir deshalb mal auf die Berechtigungen des Programms "/usr/bin/passwd":
stefan@stefan:~% ls -l /usr/bin/passwd -rwsr-xr-x 1 root root 47032 Jul 15 21:29 /usr/bin/passwd
Da fällt auf, dass an der Stelle, wo sonst beim Besitzer ein "x" steht, jetzt ein "s" steht. Dieses kleine "s" zeigt an, dass das SUID-Bit gesetzt ist. Was passiert jetzt, wenn ein "normaler" Benutzer das Programm "passwd" aufruft um sein Passwort zu ändern? Das System prüft, ob der Benutzer das Recht hat, das Programm zu starten. Da der Benutzer über "other" die Rechte "r-x" besitzt, kann der Benutzer das Programm aufrufen. Jetzt prüft das System zusätzlich, ob das SUID-Bit gesetzt ist. Ist das der Fall, wie bei dem Programm "passwd", erhält der Benutzer ein ZUSÄTZLICHE UID, nämlich die UID des Besitzers des Programms. Damit hat der Benutzer für die Laufzeit des Programms zwei UIDs, seine
eigene und die des "root". Da der "root" Schreibrechte an der Datei "/etc/passwd" hat, kann der Benutzer jetzt sein Passwort ändern. Programme, bei denen das SUID-Bit gesetzt ist, lassen sich nicht im Hintergrund starten. Das wäre auch fatal, da dann der Benutzer im Vordergrund "root"-Rechte hätte.
Das Setzen des SUID-Bits ist nur sinnvoll auf Binärdateien. Das Recht können Sie mit dem Kommando "chmod u+s <Programm>" setzen und entfernen mit "chmod u-s <Programm>". Damit das SUID-Bit genutzt werden kann, muss auch immer für den
Besitzer das "x"-Bit gesetzt sein. Da nach dem Setzen des SUID-Bits an der Stelle des "x" jetzt immer ein "s" steht, können Sie das gesetzte "x"-Bit daran erkennen, dass es sich bei dem "s" um ein kleines "s" handelt. Würde an der Stelle ein großes "S" stehen, wäre das "x"-Bit nicht gesetzt.
Das SGID-Bit
Mit dem SGID-Bit können Sie die Verwaltung der Rechtestruktur in Ihrem Dateisystem beeinflussen. Normalerweise gibt es bei Linux keine Vererbung der Berechtigungen im Dateisystem, aber durch den Einsatz des SGID-Bits können Sie das in einem bestimmten Rahmen ändern. Wenn Sie an einem Verzeichnis das SGID-Bit setzen, wird ab diesem Zeitpunkt jeder neue Eintrag unterhalb des Verzeichnisses immer der Gruppe gehören, die in diesem Verzeichnis als besitzende Gruppe eingetragen ist. Das SGID-Bit vererbt sich auch auf alle neu erstellten Unterverzeichnisse, die nach dem Setzen des SGID-Bits erzeugt werden. Wenn Sie auf Ihrer Verzeichnisstruktur das SGID-Bit an den einzelnen Abteilungsverzeichnissen setzen, gehören anschließend alle Einträge der entsprechenden Gruppe, ohne dass ein Benutzer seine Standardgruppe ändern müsste. Zusammen mit einer angepassten Umask können Sie dann bestimmte Verzeichnisse gezielt einer Gruppe zuordnen und die Rechte bestimmen. Mehr dazu folgt später im praktischen Teil dieses Artikels.
Der Einsatz des SGID-Bits ist nur sinnvoll, wenn es auf Verzeichnisse gesetzt wird. Es wird mit dem Kommando "chmod g+s <Verzeichnis>" gesetzt. Hier ein Beispiel:
stefan@stefan:~% chmod g+s verzeichnis1 stefan@stefan:~% ls -ld verzeichnis1 drwxr-sr-x 2 stefan users 4096 Aug 4 11:34 verzeichnis1 stefan@stefan:~% chgrp cdrom verzeichnis1 stefan@stefan:ueb~% cd verzeichnis1 stefan@stefan:~/verzeichnis1% mkdir verzeichnis1a stefan@stefan:~/verzeichnis1% ls -ld verzeichnis1a drwxr-sr-x 2 stefan cdrom 4096 Aug 4 17:31 verzeichnis1a
Hier sehen Sie, dass das neue Verzeichnis der neu zugeordneten Gruppe "cdrom" gehört und das SGID-Bit am Verzeichnis "verzeichnis1" gesetzt wurde. Auch das neue Unterverzeichnis "verzeichnis1/verzeichnis1a" hat das SGID-Bit gesetzt.
Das Sticky-Bit
Der Name dieses Bits stammt von seiner ursprünglichen Bedeutung. Wurde dieses Bit auf ein ausführbares Programm vom "root" gesetzt, dann blieb das Programm nach Beendigung im Arbeitsspeicher "kleben". Beim nächsten Aufruf wurde das Programm dann direkt aus dem Arbeitsspeicher gestartet. Dadurch wurde der Startvorgang des Programms beschleunigt. Linux nutzt das Sticky-Bit aber anders. Wenn Sie das Sticky-Bit an einem Verzeichnis setzen, kann nur noch der Besitzer einer Datei in dem Verzeichnis diese auch löschen. Auch wenn ein anderer Benutzer am Verzeichnis die Rechte "r,w,x" besitzt, ist er nicht berechtigt eine Datei zu löschen. Das Sticky-Bit macht nur Sinn, wenn es auf Verzeichnissen gesetzt wird. Das Sticky-Bit setzen Sie mit dem Kommando "chmod o+t <Verzeichnis>". Ein Beispiel:
stefan@stefan:~% mkdir verzeichnis2 stefan@stefan:~% chmod g+w,o+t verzeichnis2 stefan@stefan:~% ls -ld verzeichnis2 drwxrwxr-t 2 stefan users 4096 Aug 4 18:02 verzeichnis2 stefan@stefan:~% cd verzeichnis2 stefan@stefan:~/verzeichnis2% touch datei2 stefan@stefan:~/verzeichnis2% ls -l datei2 -rw-r--r-- 1 stefan users 0 Aug 4 18:04 datei2 stefan@stefan:berechtigungen-ia/verzeichnis2% su stka Passwort: stka@stefan:/home/stefan/verzeichnis2% rm datei2 rm: Normale leere Datei (schreibgeschützt) »datei2“ entfernen? y rm: das Entfernen von »datei2“ ist nicht möglich: Vorgang nicht zulässig
Sie sehen hier, obwohl der Benutzer "stka" alle Rechte am Verzeichnis "verzeichnis2" über die Gruppe "users" (in der er Mitglied ist) erhält, kann er die Datei in dem Verzeichnis nicht löschen. Auch die Meldung ist eine ganz andere, als wenn ihm das Recht fehlen würde. Hier wird jetzt auf Grund des Sticky-Bits der Vorgang untersagt. Das Sticky-Bit ist ein sehr gutes Mittel, um in Verzeichnissen auf die mehrere Benutzer Zugriff haben, ein versehentliches Löschen von Dateien durch Nichtbesitzer zu verhindern. Das Bit schützt aber nicht vor der Veränderung des Inhalts von Dateien.
Die erweiterten POSIX-ACLs
Aber was tun Sie, wenn Sie an einem Verzeichnis unterschiedliche Rechte für unterschiedliche Gruppen vergeben wollen? Diese Aufgabe können Sie nicht mehr mit den einfachen Dateisystemrechten lösen. Dafür benötigen Sie die Access Control Lists (ACL). Hier geht es darum, die Dateisystemrechte zu erweitern. Mithilfe der ACL ist es möglich, dass mehrere Gruppen oder Benutzer an einer Datei oder einem Verzeichnis unterschiedliche Rechte erhalten. Damit Sie die ACLs nutzen können, müssen Sie als Erstes das Dateisystem für die ACL-Unterstützung anpassen. Alle gängigen Dateisysteme wie ext2, ext3, ext4, reiserfs und xfs unterstützen ACLs. Aber die ACLs müssen eventuell beim Mounten des Dateisystems als Option mit angegeben werden. Sie können die entsprechende Option natürlich auch direkt in dem Eintrag der "/etc/fstab" mit angeben, so werden die ACLs auch bei einem Systemstart sofort wieder aktiviert.
Warum nur "eventuell"? Weil bei vielen aktuellen Distributionen die Dateisysteme schon so kompiliert wurden, dass sie ACLs unterstützen. Wenn Sie die in diesem Abschnitt besprochenen Beispiele auf Ihrem System nachvollziehen können, ohne die Datei "/etc/fstab" anpassen zu müssen, dann unterstützt Ihr Dateisystem die ACLs ohne dass Sie weitere Optionen angeben müssen. Sollte das nicht der Fall sein, müssen Sie die Einträge in Ihrer "/etc/fstab" wie folgt anpassen:
/dev/hdb1 /daten ext4 errors=remount-ro,acl 0 0
Hier wurde für eine Datenpartition die Option "acl" hinzugefügt. Nach einem "remount" mit dem Kommando "mount -o remount,rw /daten" stehen dann auf dieser Partition die ACLs zur Verfügung. Bei den ACLs wird zwischen den einfache ACLs und den default ACLs unterschieden. Zur Verwaltung der ACLs gibt es die Kommandos "setfacl" zum Setzen der ACLs und "getfacl" zum Auslesen der ACLs. Wenn diese Programme auf Ihrem System nicht vorhanden sind, müssen Sie das Paket "acl" nachinstallieren.
Die einfachen ACLs
Einfache ACLs gelten nur für das Verzeichnis oder die Datei, auf die sie angewendet wurden. Die einfachen ACLs werden nicht vererbt. Das folgende Listing zeigt, wie eine ACL auf ein Verzeichnis gesetzt wird:
stefan@stefan:~% mkdir verzeichnis3 stefan@stefan:~% ls -ld verzeichnis3 drwxr-xr-x 2 stefan users 4096 Aug 4 18:51 verzeichnis3 stefan@stefan:~% setfacl -m g:cdrom:rx verzeichnis3 stefan@stefan:~% ls -ld verzeichnis3 drwxr-xr-x+ 2 stefan users 4096 Aug 4 18:51 verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx group::r-x group:cdrom:r-x mask::r-x other::r-x
Im ersten Teil des Beispiels wird ein neues Verzeichnis angelegt und die Rechte aufgelistet. Im zweiten Teil wird dann mit dem Kommando "setfacl -m g:cdrom:rx verzeichnis3" ein ACL gesetzt. Die einzelnen Parameter haben dabei die folgende Bedeutung:
- -m
Mit dieser Option "-m" wird das Kommando "setfacl" angewiesen, die ACL eines Eintrages zu modifizieren. - - g:cdrom:rx verzeichnis3
Eine Gruppe (bestimmt durch den Parameter "g") "cdrom" erhält die Rechte "rx" am "verzeichnis3"
Die Reihenfolge der Parameter muss dabei eingehalten werden.
Im dritten Teil werden die Rechte des Verzeichnisses "verzeichnis3" nochmal aufgelistet. Hier sehen Sie, dass nach den Rechten jetzt ein "+" zu sehen ist. Dieses "+" weist darauf hin, dass an dem Eintrag im Dateisystem ACLs gesetzt sind. Dann wird die ACL des Verzeichnisses "verzeichnis3" aufgelistet. Hier sehen Sie jetzt, dass neben der Gruppe "users" die Gruppe "cdrom" Rechte erhalten hat.
ACHTUNG: Wenn Sie auf einem Eintrag im Dateisystem – egal ob bei einem Verzeichnis oder einer Datei – eine ACL gesetzt haben, dürfen Sie von dem Moment an keine Berechtigungen mehr mit dem Kommando "chmod" ändern. Denn dann ändern Sie nicht mehr die Rechte sondern nur eine ACL-Maske. Diese Maske kann nur Rechte ausfiltern. Sprich: ein Recht, das dort nicht gesetzt ist, kann auch keine Gruppe oder Benutzer erhalten.
Um das Verhalten zu verdeutlichen, folgt hier ein Beispiel:
stefan@stefan:~% chmod g-r verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx group::r-x #effective:--x group:cdrom:r-x #effective:--x mask::--x other::r-x
Hier sehen Sie, dass die Gruppen nur noch das effektive Recht "x" besitzen, durch die Maske wird das "r"-Recht ausgefiltert. Wenn das Recht mit "chmod" wieder zurückgesetzt wird, wird auch die Maske wieder zurückgesetzt. Was passiert aber, wenn die besitzende Gruppe (so wie im Beispiel) nur die Rechte "r-x" besitzt und Sie für eine andere Gruppe die Rechte "rwx" setzen wollen? Denn in der Standardberechtigung fehlt ja das "w"-Recht. Da es sich bei den Berechtigungen aber um einen Filter handelt, müsste das "w"-Recht auch für eine andere Gruppe nicht wirksam sein. Aber das ist nicht so, wie das folgende Listing zeigt:
stefan@stefan:~% setfacl -m g:cdrom:rwx verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx group::r-x group:cdrom:rwx mask::rwx other::r-x
Obwohl die besitzende Gruppe nur die Rechte "r-x" besitzt, hat die Gruppe "cdrom" alle Rechte am Verzeichnis. Erst eine nachträgliche Veränderung der Berechtigungsliste verändert die Maske. Selbstverständlich können Sie auch einem einzelnen Benutzer Rechte über ACLs vergeben. Das Listing zeigt diesen Vorgang:
stefan@stefan:~% setfacl -m u:stka:rwx verzeichnis3 stefan@stefan:~% getfacl verzeichnis3 # file: verzeichnis3 # owner: stefan # group: users user::rwx user:stka:rwx group::r-x group:cdrom:rwx mask::rwx other::r-x
Wenn Sie jetzt in dem Verzeichnis eine neue Datei oder Verzeichnis erstellen, werden Sie feststellen, dass die ACLs nicht auf die neuen Einträge übernommen wurden. Damit die ACLs auf neue Einträge vererbt werden, müssen Sie die "defaults ACLs" an Verzeichnissen setzen.
Die default ACLs
Bis jetzt waren alle ACLs immer nur für den Eintrag gültig, auf dem Sie die ACL gesetzt hatten. Mit den default ACLs können Sie jetzt Berechtigungen auf ein Verzeichnis setzen, die sich dann an alle darunter neu erstellten Einträge vererben. Das Listing zeigt wie Sie default ACLs setzen können:
stefan@stefan:~% mkdir verz-def-acl stefan@stefan:~% setfacl -d -m g:cdrom:rwx verz-def-acl stefan@stefan:~% ls -ld verz-def-acl drwxr-xr-x+ 2 stefan users 4096 Aug 6 10:57 verz-def-acl stefan@stefan:~% getfacl verz-def-acl # file: verz-def-acl # owner: stefan # group: users user::rwx group::r-x other::r-x default:user::rwx default:group::r-x default:group:cdrom:rwx default:mask::rwx default:other::r-x
Mit der setfacl-Option "-d" erstellen Sie ein default ACL. Wenn Sie sich das Verzeichnis mit "ls" anzeigen lassen, sehen Sie auch hier wieder das Pluszeichen am Ende der Rechteliste, welches auf das Vorhandensein von ACL hinweist. Lassen Sie sich jetzt die ACLs mittels "getfacl" anzeigen, sehen Sie, dass alle ACLs als "default ACLs" eingetragen wurden. Wenn Sie jetzt in dem Verzeichnis ein neues Verzeichnis oder eine neue Datei anlegen, werden diese Einträge die ACLs übernehmen. In nächsten Listing möchte ich Sie noch einmal auf das Verhalten beim Anlegen einer Datei hinsichtlich des x-Rechts aufmerksam machen. In den "default ACLs" ist ja das x-Recht immer mit gesetzt und wird somit auf alle neuen Einträge übernommen. Auch auf Dateien werden diese "default ACLs" gesetzt. Wenn Sie jetzt aber eine leere Datei oder eine Datei einer Anwendung erstellen, vergibt das Betriebssystem das x-Recht nicht an diese Datei. In den ACLs ist es aber gesetzt, deshalb sehen Sie bei dem Aufruf von "getfacl" den Hinweis "effective". Das ist kein Fehler, das ist das richtige Verhalten.
stefan@stefan:~% touch dat-acl stefan@stefan:~% getfacl dat-acl # file: dat-acl # owner: stefan # group: users user::rw- group::r-x #effective:r-- group:cdrom:rwx #effective:rw- mask::rw- other::r--
Löschen von ACLs
Sowohl die einfachen, als auch die default ACLs löschen Sie mit dem Kommando "setfacl". Beim Entfernen der ACLs wird zwischen den unterschiedlichen ACLs unterschieden. Sie müssen vor dem Löschen wissen, ob Sie ein einfache oder eine default ACL entfernen wollen. Das folgende Listing zeigt den Vorgang des Löschens einer default ACL:
stefan@stefan:~/verz-def-acl% setfacl -k verz-acl stefan@stefan:~/verz-def-acl% getfacl verz-acl # file: verz-acl # owner: stefan # group: users user::rwx group::r-x group:cdrom:rwx mask::rwx other::r-x stefan@stefan:berechtigungen-ia/verz-def-acl% ls -ld verz-acl drwxrwxr-x+ 2 stefan users 4096 Aug 6 11:05 verz-acl
Durch die Option "-k" werden alle default ACLs des Eintrags gelöscht, die einfachen ACLs bleiben erhalten. Mit der Option "-b" löschen Sie die einfachen ACLs:
stefan@stefan:~/verz-def-acl% setfacl -b verz-acl stefan@stefan:~/verz-def-acl% ls -ld verz-acl drwxr-xr-x 2 stefan users 4096 Aug 6 11:05 verz-acl
Und dann ist da noch das Folgende
Bis zu diesem Zeitpunkt haben wir immer nur ACLs auf einzelne Einträge gesetzt oder entfernt. Selbstverständlich können Sie die ACLs auch rekursiv über einen ganzen Teilbaum setzen oder löschen. Auch ein Sichern der ACLs mittels "getfacl" können Sie rekursiv durchführen und diese Sicherung später mittels "setfacl" wieder einspielen. Das ist besonders dann wichtig, wenn Sie eine Backup-Software einsetzen, die keine ACLs sichern kann. Dann können Sie die ACLs getrennt in eine Datei sichern und anschließend – bei einem eventuellen Recovery des Dateisystems – aus der Datei wieder einspielen. Sowohl das Kommando "setfacl" als auch das Kommando "getfacl" kennen die Option "-R" für das rekursive Löschen oder Anzeigen. Im folgenden Listing sehen Sie ein paar Beispiele für die Verwendung von "setfacl" und "getfacl":
stefan@stefan:~% getfacl -R verz-def-acl stefan@stefan:~% getfacl -R verz-def-acl > sicherung.acl stefan@stefan:~% setfacl -R -m g:cdrom:rwx verz-def-acl stefan@stefan:~% setfacl --restore=sicherung.acl
Im ersten Beispiel werden alle ACLs aller Einträge angezeigt. Im zweiten Beispiel werden die Einträge in eine Datei gesichert. Beim dritten Beispiel werden alle Einträge ab dem angegeben Verzeichnis mit einer ACL belegt. Das vierte Beispiel zeigt dann, wie Sie die ACLs aus einer Datei wieder einspielen können. Wenn Sie jetzt die ACLs in Ihrem Dateisystem anwenden wollen, dann stellen Sie schnell fest, dass Dateien und Verzeichnisse unterschiedliche ACLs benötigen. Zum Beispiel braucht ein Textdokument kein x-Recht, aber ein Verzeichnis benötigt dieses Recht auf jeden Fall, denn sonst kann nicht in das Verzeichnis gewechselt werden. Deshalb können Sie das Kommando "setfacl" sehr gut zusammen mit dem Kommando "find" einsetzen. Im nächsten Listing zeige ich Ihnen, wie Sie für alle Dateien und Verzeichnisse ab einem bestimmten Punkt ACLs setzen können:
stefan@stefan:~% find . -type d -exec setfacl -d -m g:cdrom:rwx {} \;
stefan@stefan:~% find . -type f -exec setfacl -m g:cdrom:r {} \;
Im ersten Beispiel werden alle Verzeichnisse ab dem aktuellen Verzeichnis gesucht und anschließend wird für jedes Verzeichnis die entsprechende default ACL gesetzt. Im zweiten Beispiel wird nach allen Dateien gesucht und die einfache ACL gesetzt. Die Option "-d" darf hier nicht verwendet werden, da sich default ACLs nur auf Verzeichnisse setzen lassen. Verwenden Sie trotzdem die Option "-d", werden für die Dateien Fehlermeldungen ausgeworfen.
Zusammen mit den Berechtigungen, den "special-Bits" und den ACLs stehen Ihnen jetzt eine Vielzahl von Möglichkeiten zur Verfügung, die Rechte in Ihrem Dateisystem gezielt zu setzen.
Die erweiterten Attribute
Auch Linux kennt im Dateisystem erweiterte Attribute mit denen Sie bestimmte Einschränkungen beim Zugriff auf Dateien einrichten können. Diese erweiterten Attribute möchte ich an dieser Stelle vorstellen. Um die Attribute verwenden zu können muss das Dateisystem vorbereitet werden. Denn auch für die Attribute gibt es eine Mountoption, die Sie wieder bei einigen älteren Distributionen in der Datei "/etc/fstab" setzen müssen. Das Listing zeigt Ihnen den angepassten Eintrag in der Datei:
/dev/hdb1 /daten ext4 errors=remount-ro,acl,user_xattr 0 0
Nach einem "remount" des Dateisystems stehen Ihnen dann die erweiterten Attribute zur Verfügung. Die Attribute setzen Sie mit dem Kommando "chattr". Auflisten können Sie die Attribute mit dem Kommando "lsattr", sollten diese Kommandos auf Ihrem System nicht vorhanden sein, müssen Sie das Paket "attr" nachinstallieren.
Bei den Attributen gibt es zwei Gruppen: Die Attribute der einen Gruppe können von "normalen" Benutzern gesetzt werden, die Attribute der anderen Gruppe können nur vom "root" gesetzt werden. Unter den Attributen gibt es einige, die sowieso selten benötigt werden, diese sollen hier nicht betrachtet werden. Aber einige der Attribute können im täglichen Umgang mit Dateisystemrechten nützlich sein. Diese werden ich Ihnen hier erklären.
Attribute, die jeder setzen kann
- Das Attribut "d"
Durch Setzen dieses Attributs verhindern Sie, dass die entsprechende Datei bei einer Datensicherung mit dem Kommando "dump" mitgesichert wird. - Das Attribut "s"
Wenn ein Benutzer dieses Attribut setzt, wird die Datei beim Löschen mit Nullen überschrieben. - Das Attribut "A"
Wenn Sie das Attribut "A" setzen, wird die "atime" der Datei nicht verändert. Das kann die Performance beim Schreiben erhöhen. Besser ist es aber, hier die Option "noatime" für das gesamte Dateisystem in der Datei "/etc/fstab" zu setzen.
Attribute die nur der "root" setzen kann
- Das Attribut "a"
Wenn Sie als "root" dieses Attribut auf eine Datei setzen, kann der Inhalt der Datei nicht mehr geändertwerden, es können nur noch Daten an die Datei angehängt werden. Hier sehen Sie dazu ein Beispiel:root@stefan:~# touch datei1.txt root@stefan:~# chattr +a datei1.txt root@stefan:~# lsattr datei1.txt -----a------------- datei1.txt root@stefan:~# echo "Eine neue Zeile" > datei1.txt -bash: datei1.txt: Die Operation ist nicht erlaubt root@stefan:~# echo "Eine neue Zeile anhängen " >> datei1.txt
Mit dem ersten Kommando wird einfach eine leere Datei erzeugt, bei der im zweiten Schritt das Attribut "a" gesetzt wird. Im Anschluss wird versucht, eine Zeile in die Datei mit einer einfachen Umleitung zu schreiben. Diese Operation wird aufgrund des Attributs verboten. Selbst der "root" kann den Inhalt der Datei nicht verändern, solange das Attribute "a" gesetzt ist. Erst im nächsten Schritt wird eine Zeile an die Datei angehängt, und jetzt ist das
Schreiben in die Datei möglich.
- Das Attribut "i"
Durch das Attribut "i" wird die Datei immun gegen das Ändern, Umbenennen und Löschen. Auch der "root" kann eine Datei mit diesem Attribut nicht löschen, ohne vorher das Attribut zurückzusetzen. Auch dazu sehen Sie ein Beispiel: root@stefan:~# chattr +i datei1.txt
root@stefan:~# lsattr datei1.txt ----i-------------- datei1.txt root@stefan:~# echo "Eine zweite Zeile anhängen " >> datei1.txt -bash: datei1.txt: Keine Berechtigung root@stefan:~# ls -l datei1.txt -rw-r--r-- 1 root stefan 27 27. Jul 18:02 datei1.txt root@stefan:~# rm datei1.txt rm: Entfernen von "datei1.txt" nicht möglich: Die Operation ist nicht erlaubt root@stefan:~# mv datei1.txt datei1a.txt mv: Verschieben von "datei1.txt" nach "datei1a.txt" nicht möglich: Die Operation ist nicht erlaubt root@stefan:~# chattr -i datei1.txt root@stefan:~# rm datei1.txt
Alle Aktionen wurden hier als Benutzer "root" durchgeführt. Wie Sie sehen, ist danach keine Aktion mit der Datei mehr möglich. Erst wenn das Attribut von der Datei entfernt wird, kann die Datei wieder gelöscht werden.
Weitere Attribute
Neben diesen Attributen gibt es noch weitere Attribute, die zum Teil experimentell oder nicht von so großer Bedeutung für den täglichen Gebrauch sind. Alle Attribute werden ausführlich in der Manpage zu "chattr" beschrieben. Wenn Sie die Attribute verwenden wollen, sollten Sie immer einen Blick auf diese Manpage werfen, um mögliche Komplikationen zu vermeiden, denn nicht alle Attribute funktionieren in allen Dateisystemen.
Ein praktisches Beispiel
Nach dem im ersten Teil die Grundlagen besprochen wurden, will ich Ihnen jetzt anhand eines Beispiels zeigen, wie Sie die Dateisystemrechte planen können. Natürlich ist es in so einem Artikel nicht möglich, alle Eventualitäten abzudecken, aber eine gewisse Planungsgrundlage kann ich Ihnen hier an die Hand geben. In dem Beispiel werde ich eine Verzeichnisstruktur erstellen, die sich auf ein Unternehmen mit mehreren Abteilungen bezieht, in dem jede Abteilung unterschiedliche Zugriffsrechte auf verschiedene Ordner benötigt. Desweiteren soll ein Verzeichnis für alle Mitarbeiter existieren, das als Austauschverzeichnis für Daten dient und in das alle Mitarbeiter schreiben dürfen, aber nur der Besitzer einer Datei soll diese auch löschen können. Um die Verzeichnisse hier abbilden zu können, werde ich das Kommando "tree" verwenden. Sollte das Kommando bei Ihnen nicht installiert sein, müssen Sie das Paket "tree" nachinstallieren.
Im Beispiel wird alles auf einer lokalen Maschine eingerichtet. In der Praxis werden Sie die Daten auf einem Server verwalten und die Benutzerverwaltung zentral durchführen. Da sich die ACLs und die Dateisystemrechte via NFS auf Clients exportieren lassen, können Sie das Beispiel auch auf einem Fileserver mit einer zentralen Benutzerverwaltung und angebundenen Clients einrichten und testen.
Beschreibung der Umgebung
Die Firma besteht aus drei Abteilungen: Der Verwaltung, der Produktion und der Geschäftsleitung. Jede Abteilung soll ein eigenes Verzeichnis erhalten, in der nur diese Abteilung Schreibrechte haben soll. Die Geschäftsleitung möchte auf allen Abteilungsverzeichnissen das Leserecht haben. Alle Dateien in den Abteilungsverzeichnissen sollen immer der Abteilungsgruppe gehören. Die Rechte aller neuen Einträge sollen immer mit der Umask 007 angelegt werden. Es soll ein Gruppe "mitarbeiter" geben, in der alle Mitarbeiter Mitglied sind. Über die Gruppe sollen die Rechte am Austauschverzeichnis gesteuert werden.
Setzen der Umask
Damit alle Mitarbeiter auf allen Clients die gewünschte Umask von 007 erhalten, müssen Sie, je nach Distribution, entweder direkt die Datei "/etc/profile" oder die Datei "/etc/login.defs" anpassen. Diese Anpassung müssen Sie an jedem Client durchführen.
Einrichten der Verzeichnisstruktur
Um die Berechtigungen gut staffeln zu können, wird ein übergeordnetes Verzeichnis für die Abteilungen eingerichtet. An diesem Verzeichnis erhalten alle Mitarbeiter über die Gruppe "mitarbeiter" die Rechte "rx", damit sie durch das Verzeichnis in das eigentliche Abteilungsverzeichnis wechseln können. Das wäre auf einem Server auch das Verzeichnis, das über NFS an alle Clients freigegeben würde. Das folgende Listing zeigt das Anlegen der Verzeichnisstruktur:
root@stefan:~# mkdir /abteilungen root@stefan:~# cd /abteilungen root@stefan:/abteilungen# mkdir verwaltung produktion geschaeftsleitung root@stefan:/abteilungen# mkdir /alle
Nach dem alle benötigten Verzeichnisse angelegt wurden, zeigt das nächste Listing, wie Sie die entsprechenden Rechte setzen müssen:
root@stefan:/# chmod 750 /abteilungen root@stefan:/# chmod 2770 /abteilungen/* root@stefan:/# chgrp mitarbeiter /abteilungen root@stefan:/# chgrp verwaltung /abteilungen/verwaltung root@stefan:/# chgrp produktion /abteilungen/produktion root@stefan:/# chgrp geschaeftsleitung /abteilungen/geschaeftsleitung root@stefan:/# tree -p abteilungen abteilungen --- [drwxrws---] geschaeftsleitung --- [drwxrws---] produktion --- [drwxrws---] verwaltung root@stefan:/# chgrp mitarbeiter /alle root@stefan:/# chmod 3770 /alle root@stefan:/# ls -ld /alle drwxrws--T 2 root mitarbeiter 4096 Aug 10 13:04 /alle
Jetzt kann jede Abteilung in ihrem Verzeichnis Daten speichern. Durch das gesetzte SGID-Bit gehören alle Dateien immer der Abteilungsgruppe. Über "other" werden keine Rechte vergeben. Am Verzeichnis "/alle" haben alle Mitarbeiter die Rechte "rwx". Dadurch können sie Einträge erzeugen und Inhalte ändern. Aber nur die Einträge, die ihnen gehören können sie löschen oder umbenennen. Jetzt fehlt nur noch, dass die Geschäftsleitung an allen anderen Abteilungsverzeichnissen das Leserecht an allen Einträge erhält. Das steuern Sie über die default ACLs an den Verzeichnissen. Das Listing zeigt die entsprechenden
Kommandos:
root@stefan:/# setfacl -d -m g:geschaeftsleitung:rx /abteilungen/verwaltung root@stefan:/# setfacl -d -m g:geschaeftsleitung:rx /abteilungen/produktion
Jetzt können alle Mitglieder der Gruppe "geschaeftsleitung" in allen Verzeichnissen mindestens lesen. Dadurch, dass die ACLs als default ACLs gesetzt wurden, vererben sich die ACLs immer weiter und auch in neu angelegten Unterverzeichnissen hat die Geschäftsleitung die gewünschten Rechte.
Fazit
Ich hoffe, ich konnte Ihnen mit diesem kleinen Artikel zum Thema Dateisystemberechtigungen etwas helfen, in Zukunft einfacher Verzeichnisstrukturen für Mitarbeiter bereitzustellen und diese mit den benötigten Rechten und ACLs zu versehen.
Upgrade Debian Bookworm zu Trixie
1. Vorbereitungen
Bevor wir ein Upgrade durchführen, sollte das aktuelle System auf den letzten Stand aktualisiert werden. Zusätzlich entfernen wir nicht mehr benötigte Pakete und schaffen somit etwas mehr Platz auf der Festplatte. Alle hier gezeigten Befehle gebe ich als root-User ein. Solltet ihr nicht als root arbeiten, müsst ihr euch mittels vorangestelltem sudo entsprechende Rechte zuweisen. Sollte bei der Update ein neuer Kernel installiert werden, ist ein anschließender Reboot ratsam.
Für ein Upgrade solltet ihr über mindestens 5GB freien Speicher verfügen und ihr solltet auf Debian 12 Bookworm sein. Ein Upgrade von Debian 11 aus geht nicht.
Nun wäre es auch ratsam sich über ein Backup Gedanken zu machen. Ich nutze nur VMs auf einem Proxmox System und erstelle somit vorher ein Backup des Systems unter Proxmox.
apt update && apt dist-upgrade
apt clean
apt autoremove2. Repositories aktualisieren
Nun ändern wir die Debian Repositories und alles 3rd Party Repositories zu Trixie. Mit folgenden zwei Befehlen lässt sich das einfach bewerkstelligen. Anschließend für ihre in Update der Paketinformationen durch. Sollte es hier zu Fehlern kommen, solltet ihr nochmals eure Source Files kontrollieren. Gerade 3rd Party Repositories können hier Probleme machen. Stellt diese wieder auf Bookworm um, oder deaktiviert sie temporär durch ein vorangestelltes # im entsprechenden Source File .
sed -i 's/bookworm/trixie/g' /etc/apt/sources.list
find /etc/apt/sources.list.d -name "*.list" -exec sed -i 's/bookworm/trixie/g' {} \;
apt update3. Debian Upgrade auf Trixie
Nun kommen wir zu eigentlichen Upgrade-Prozess. Wir gehen hier den konservativen Weg und machen erst ein Upgrade ohne neue Pakete und eventuellen Abhängigkeitsproblemen aus dem Weg zu gehen. Anschließend führen wir das volle Upgrade durch. Während des Upgrades werdet ihr über Service Neustarts und Konfig-Files Updates informiert. Generell solltet ihr dem Neustart zustimmen und eure bestehende Konfiguration beibehalten, außer ihr habt dafür spezielle Gründe.
apt upgrade --without-new-pkgs
apt full-upgrade4. Nacharbeit
Wir bereinigen noch die Pakete und führen den abschließenden Reboot durch. Danach solltet ihr erfolgreich auf Debain Trixie upgegraded haben.
apt autoremove
apt autoclean
rebootNach dem Neustart kontrollieren wir die installierte Debian Version und überprüfen ob wirklich alle Pakete aktualisiert wurden.
cat /etc/os-release
apt update
apt list --upgradableNebenstehend seht ihr das euer System nun auf Debian 13 Trixie läuft.
6. Neue Debian Sources aktivieren in Trixie
Aktuell nicht notwendig aber bereits jetzt empfehlenswert ist die Umstellung der Quellenliste auf das neue deb822 Format. Dafür gibt es ein Tool, welche eure Quellenlisten umstellt, bzw. euch dabei hilft. Das Tool bietet sogar eine Simulation an.
apt modernize-sources
The following files need modernizing:
- /etc/apt/sources.list
- /etc/apt/sources.list.d/docker.list
Modernizing will replace .list files with the new .sources format,
add Signed-By values where they can be determined automatically,
and save the old files into .list.bak files.
This command supports the 'signed-by' and 'trusted' options. If you
have specified other options inside [] brackets, please transfer them
manually to the output files; see sources.list(5) for a mapping.
For a simulation, respond N in the following prompt.
Rewrite 2 sources? [Y/n] y
Modernizing /etc/apt/sources.list...
- Writing /etc/apt/sources.list.d/debian.sources
Modernizing /etc/apt/sources.list.d/docker.list...
- Writing /etc/apt/sources.list.d/docker.sourcesIch hoffe diese Beitrag konnte euch bei der Umstellung helfen. Ich habe damit bereits drei Systeme erfolgreich umgestellt und bisher keine Probleme gehabt. Jedoch hier nochmals der Hinweis, immer vorher ein Backup erstellen!
7. Ding die bei mir Probleme machten
Danke für den Tipp die systcl.conf in die /etc/sysctl.d/ zu verschieben, nun klappt auch das Wireguard wieder 🙂 .
Antworten
Björn
18. August 2025 um 14:50 Uhr
Hab ich zwar so nicht geschrieben, aber deine Methode ist natürlich besser. 😉
Danke.
Hallo,
danke für die Anleitung hat super funktioniert.
Aber ich bekomme immer folgenden Hinweis:
All packages are up to date.
Notice: Missing Signed-By in the sources.list(5) entry for ‚http://archive.raspberrypi.com/debian‘
Braucht man überhaupt noch das „http://archive.raspberrypi.com/debian“ ?
Gruß
Tobi
Jens
13. Februar 2026 um 12:15 Uhr
Moin Björn!
Dane für die klare Anleitung. Hat bei mir soweit gut funktioniert. Leider habe ich mit dem letzten Schritt (apt modernize-sources) Schwierigkeiten. Er sagt, dass er für die Docker Quellen kein „Signed-By“ finden kann:
Modernizing /etc/apt/sources.list.d/download_docker_com_linux_debian.list…
– Writing /etc/apt/sources.list.d/download_docker_com_linux_debian.sources
Warning: Could not determine Signed-By for URIs: https://download.docker.com/linux/debian/, Suites: trixie
Du kannst dir dazu die Docker Dokumentation anschauen. Unter 1. Set up Docker’s apt repository. findest du die nötigen Infos, wie du den Key herunterlädst und das nötige Source File erzeugst, bzw. wie es aussehen sollte.
Thinclient
CPU-Vergleich
Igel 350c Igel340C HP T520

AMD Ryzen Embedded R1505G vs AMD GX-424CC


Comparison of the technical characteristics between the processors, with the AMD Ryzen Embedded R1505G on one side and the AMD GX-424CC on the other side, also their respective performances with the benchmarks. The first is dedicated to the mini desktop sector, It has 2 cores, 4 threads, a maximum frequency of 3,3GHz. The second is used on the mini desktop segment, it has a total of 4 cores, 4 threads, its turbo frequency is set to 2,4 GHz. The following table also compares the lithography, the number of transistors (if indicated), the amount of cache memory, the maximum RAM memory capacity, the type of memory accepted, the release date, the maximum number of PCIe lanes, the values obtained in Geekbench and Cinebench.
Specification comparison:
| Processor | AMD Ryzen Embedded R1505G | AMD GX-424CC | ||||||
| Market (main) | Mini desktop | Mini desktop | ||||||
| ISA | x86-64 (64 bit) | x86-64 (64 bit) | ||||||
| Microarchitecture | Zen+ | Puma | ||||||
| Core name | Banded Kestrel | Steppe Eagle | ||||||
| Family | Ryzen Embedded | AMD GX | ||||||
| Part number(s), S-Spec |
YE1505C4T2OFG |
GE424CIXJ44JB |
||||||
| Release date | Q2 2019 | Q2 2014 | ||||||
| Lithography | 14 nm | 28 nm | ||||||
| Cores | 2 | 4 | ||||||
| Threads | 4 | 4 | ||||||
| Base frequency | 2,4 GHz | 2,4 GHz | ||||||
| Turbo frequency | 3,3 GHz | - | ||||||
| High performance cores |
2 Cores 4 Threads @ 2,4 / 3,3 GHz |
4 Cores 4 Threads @ 2,4 GHz |
||||||
| Cache memory |
4 MB |
2 MB |
||||||
| Max memory capacity | 32 GB | 8 GB | ||||||
| Memory types |
DDR4-2400 |
DDR3-1866 |
||||||
| Max # of memory channels | 2 | 1 | ||||||
| Max PCIe lanes | 8 | 6 | ||||||
| TDP |
25 W |
25 W |
||||||
| GPU integrated graphics | AMD Radeon Vega 3 (Picasso) | AMD Radeon R5E | ||||||
| GPU cores | 3 | 2 | ||||||
| GPU shading units | 192 | 128 | ||||||
| GPU base clock | 300 MHz | 497 MHz | ||||||
| GPU boost clock | 1000 MHz | 497 MHz | ||||||
| GPU FP32 floating point | 384 GFLOPS | 167,6 GFLOPS | ||||||
| Socket(s) | FP5, BGA1140 | FT3b, BGA769 | ||||||
| Compatible motherboard | Socket FP5 Motherboard  |
- | ||||||
| Maximum temperature | 105°C | 90°C | ||||||
| Crypto engine |
AES Instructions, Secure Memory Encryption |
AES Instructions |
||||||
| Security |
Enhanced Virus Protection, Platform Secure Boot |
Enhanced Virus Protection |
||||||
| PassMark single thread | 1.806 | 805 | ||||||
| PassMark CPU Mark | 3.955 | 1.732 | ||||||
| (Windows) Geekbench 4 single core |
3.390 | 1.379 | ||||||
| (Windows) Geekbench 4 multi-core |
6.433 | 3.552 | ||||||
| (Windows) Geekbench 5 single core |
724 | 284 | ||||||
| (Windows) Geekbench 5 multi-core |
1.433 | 848 | ||||||
| (SGEMM) GFLOPS Performance |
66 GFLOPS | 26,8 GFLOPS | ||||||
| (Multi-core / watt performance) Performance / watt ratio |
257 pts / W | 142 pts / W |
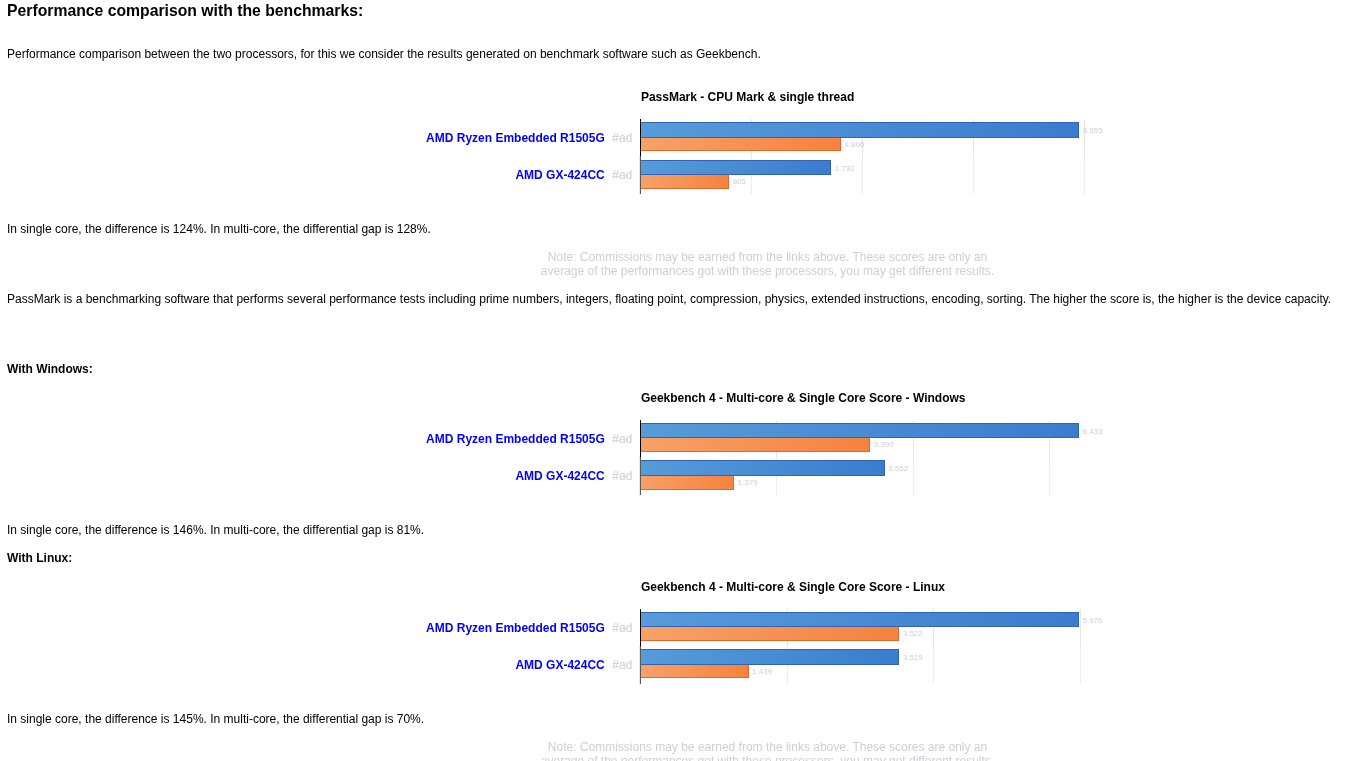
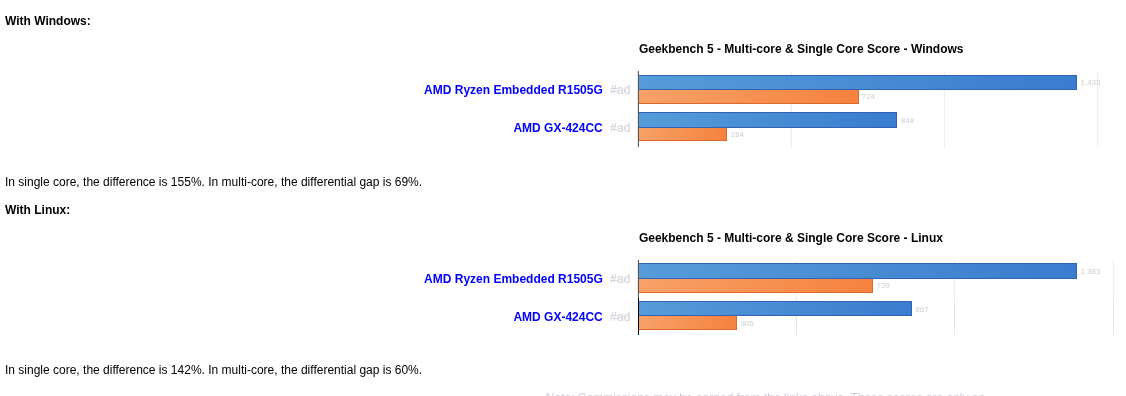
Igel M340C


My M340C came without a foot.
The M340C was part of Igel's UD3 line of thin clients.
For some unknown reason finding the launch date took some doing. I eventually found a blogger's column (dated 15th February 2016) that mentioned the imminent launch of what I believe to be the M340C. This ties in with a mention I found of the Igel Version of Windows 7 that was available on the M340C at launch. That software was released on 1st February 2016.
The UD3-LX 51 reached 'End-of Sales' in January 2021 and 'End of Maintenance' is due in January 2024.
Models
Shortly after I added the M340C to the site I heard from Bob who drew my attention to the fact that there were M340Cs around that were fitted with the less powerful AMD GX-412. I (well, Google if I'm honest) couldn't find any datasheet that tied the M340C and the GX412 SOC together. Any M340C specific datasheet I found only mentioned the GX-424CC.
Switching to searching on UD3 improved matters. I found a UD3 datasheet that had been created in October 2016. The picture of the thin client matches my M340C, the CPU is given as AMD Steppe Eagle GX-412HC 1,2 - 1,6 GHz (Quad-Core), but there is no mention of the hardware model number. By January 2019 the UD3 datasheet gives the CPU as AMD GX-424CC 2.4 GHz (Quad-Core).
Further searching found me an 'Igel Roadmap' which mentions the switch to the AMD GX-424 with availability from the end of February 2018.
The pull-out tab on Bob's M340C and my M340C match in that in each case the model name is given as IGEL-M340C. From a photo that Bob sent me it looks the motherboard and internal layout are identical.
From this we can see that, at launch, the M340C was fitted with an AMD GX-412HC (1.2GHz-1.6GHz, with Radeon R3E graphics). In early 2018 Igel upgraded the SOC in the M340C to an AMD GX-424CC (2.4GHz, Radeon R5E graphics) without any change to the model name.

How you determine exactly what you're getting I'm not too sure as there is just one obscure visual clue to help you. I found on close inspection of my M340C that it does have the words GX-424CC-QC on the reverse of the pull-out tab with the model number. (This is along with stuff like the serial number et al). Obviously a check of the information in the BIOS makes it clear but eBay vendors often provide few (or stock) photos and just cut-and-paste information they find on the Internet into their adverts. In fact, checking back, I see the M340C I bought was actually inaccurately advertised as having a 1.2GHz CPU.
What follows below are the details of my later model M340C. As to the earlier model two obvious differences are:
- CPU/Graphics are AMD GX-412HC and Radeon R3E.
- BIOS is a more conventional InsydeH20.
Specifications
The basic specs are:
Processor Type
SpeedAMD GX-424CC (Quad-Core)
2.4GHzChipset Type Built-in Memory Flash
RAM2GB(LX) 32GB(W10)
4GB(LX) 4GB(W10) max. 1x 8GBVideo Chip
Max resolutionRadeon R5E
1920 x 1200 (DVI), 3840 x 2160 (Display Port)Ports Video
Network
USB
Serial
Parallel
PS/21 x DVI-I 1 x Display Port 1.2
10/100/1000
3 x USB2.0, 1 x USB 3.0 back
1 x USB 3.0 front
none
none
KybdPower Supply
Plug
Off
Running
Idle12V 3A (label)
Coax 5.5mm/2.1mm
1W
10W
6WDimensions W x H x D 6.9cm x 21.0cm x 20.7cm
There is an optional replacement 'foot' that includes 2 x serial ports.
The M340C is available in various guises and could be running Linux or Windows 10.
CPU
The GX-424CC is a quad core CPU clocked at 2.4GHz. For those to whom it matters here is some detail from Linux's /proc/cpuinfo
vendor_id : AuthenticAMD cpu family : 22 model : 48 model name : AMD GX-424CC SOC with Radeon(TM) R5E Graphics stepping : 1 flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good acc_power nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt topoext perfctr_nb bpext ptsc perfctr_llc hw_pstate ssbd vmmcall bmi1 xsaveopt arat npt lbrv svm_lock nrip_save tsc_scale flushbyasid decodeassists pausefilter pfthreshold overflow_recov
PCI
Power Supply
The IGEL M340C uses an external 12V supply with a conventional 5.5mm/2.1mm coaxial connector. The M340C data sheet gives it power consumption as 4.7W when idle and 0.42W in sleep mode.
Expansion
There is not much space inside the M340C for adding extras, but both the Flash memory and the RAM are easily replaceable.
Flash: The flash memory is a Transcend 4GB SATA DOM plugged into a socket - top left in the photograph. When fitted the edge of it is in contact with a square rubber pillar which I assume is there to help keep it in place. The SSD measures 34mm from the edge of the socket it plugs into to its edge against the rubber pillar. You've got about another 12mm before whatever SSD you are wanting to use hits the mounting screw of the heatsink. Also, if you're fitting a longer replacement that the standard SSD, you'll need to slightly reduce the height of the rubber pillar.
The board is tracked for a mSATA socket below the SATA DOM. As usual it looks like the capacitors in the data lines are missing should you wish to try your soldering skills and put this into service.
In November 2021 I heard from Erik who had the earlier model of the M340C. His example had the mSATA socket fitted. I don't know if this is the case with all early models.
RAM:There is a single DDR3L SODIMM socket for the RAM. The 2GB Transcend SODIMM supplied with my unit is labelled: TSIT3DDR3L-02G. I successfully tried an 8GB part from Crucial: CT102464BF160B.C.16FER.
There is a JBAT1 jumper close to the backup battery for clearing the CMOS.
The short RED lead (bottom left in the board photo) is the connector to the front panel USB 3.0 socket. (Although it looks to be a SATA data lead it's just being used as a convenient board connector).
Also on the board there is an unpopulated 2 x 5 socket (J3) whose purposes are unknown (at least to me).
Configured Voltage: 1.5 V
Umbauoptionen
Minimal OS (Kiosk)
Jean28518/minimalOS
README.md
minimalOS
Einfaches Linux für Kiosks, Terminals oder sehr leichte Workstations, welches nahezu nur aus einem Webbrowser (startet optional im Vollbildmodus) besteht. Das System aktualisiert sich vollautomatisch und ist (fast) ausbruchsicher.
Alle noch vorhandenen Ausbruchstellen, lassen sich bei Bedarf entfernen.
Features
- Vollautomatische Installation und Einrichtung (Einstellungen werden in das Installationsmedium geschrieben)
- Chromium Browser geeignet für Anzeigen, Anmelde/Bestell/...-Terminals, Kiosks, Workstations, Multimedia-Station, ...
- Automatische Druckerkonfiguration (soweit von Linux unterstützt)
- Bildschirmeinstellungen über Kontextmenü (abschaltbar)
- Soundeinstellungen über Kontextmenü (abschaltbar)
- Netzwerkeinstellungen über Kontextmenü (abschaltbar)
- Sound-Steuerung über Multimedia-Tasten (abschaltbar)
- Bildschirmhelligkeit-Steuerung über entsprechende Tasten (abschaltbar)
- Touchpad/Touchscreen Support
- Vollautomatische Updates (abschaltbar)
- Neustart/Herunterfahren über Kontextmenü
- Adminkonsole für die Wartung mit Passwortschutz (Über Strg + Alt + F1 erreichbar)
- Möglichkeit zur weiteren Anpassung/Konfiguration des Systems (Debian, Openbox)
Achtung: !Das System installiert sich standardmäßig vollautomatisch auf den Rechner und löscht standardmäßig alle Partitionen!
Hardware Anforderungen
| Leerlauf | Empfohlene Mindestanforderungen | |
|---|---|---|
| RAM | 340 MB | 1 GB |
| Festplattenkapazität | 2.5 GB | 10 GB |
Unterstützte Architekturen: amd64, arm64, i386 (32bit)
.iso-Datei bauen
sudo apt install syslinux-utils git clone https://github.com/Jean28518/minimalOS.git cd minimalOS
- Unter
deb/usr/lib/minimal-os/openbox/autostartkönnen automatisch gestartete Anwendungen sowie ebenfalls der Link der Webseite, die sich standardmäßig öffnen sollen, definiert werden. - Ebenfalls kann das Hintergrundbild
deb/usr/share/backgrounds/minimal-os.jpgausgetauscht werden. - Außerdem kann das OpenBox Menü (Rechtsklick) unter
deb/usr/lib/minimal-os/menu.xmlangepasst werden. Standardmäßig ist das volle Applications-Menü deaktiviert. - In der
preseed.cfgDatei können Standard-Passwörter angepasst werden, weitere Software hinzugefügt werden (in der Zeiled-i pkgsel/include string), sowie die vollautomatische Installation unterbrochen werden (entsprechend in der Datei dokumentiert).
bash create-deb.sh
amd64
Die "normale" Architektur
bash download-debian-amd64.sh sudo bash build.sh amd
arm64
Beispielsweise für den Raspberry Pi.
bash download-debian-arm64.sh sudo bash build.sh arm
i386
Für ältere 32bit Systeme.
bash download-debian-i386.sh sudo bash build.sh 386
- Nun sollte eine minimalOS.iso Datei existieren, die wie jedes andere Linux vollautomatisch installiert werden kann (Bitte "Grafische Installation" auswählen). Das Gerät benötigt während der Installation eine Internetverbindung. Achtung: Das System formatiert (wenn nicht in der preseed-Datei auskommentiert) alle Festplatten auf dem System!
Benutzung
Gesteuert kann das System über einen Rechtsklick auf den Desktop, nachdem der Browser geschlossen wurde (Alt+F4).
Der Standard-Benutzer hat keine Root-Rechte und meldet sich vollautomatisch ohne Passworteingabe ein. Um Root zu werden, muss man auf eine andere Konsole wechseln (Beispiel: Strg + Alt + F1) und sich dann als root einloggen. Das Passwort dafür kann in der preseed.cfg konfiguriert werden und ist standardmäßig mei3eiN6.
IGEL UD3 M350C: Technische Spezifikation
Im folgenden Artikel finden Sie technische Details zum IGEL UD3-Modell M350C, seinen typischen Energieverbrauch, die Betriebsbedingungen und die Montagemöglichkeiten.
IGEL UD3 M350C Anschlüsse

Teileliste
- Endgerät
- Standfuß
- Netzteil mit integriertem DC-Kabel
- AC-Netzkabel
VORSICHT! Beachten Sie den folgenden Hinweis zur Stromversorgung:
- Schließen Sie alle Zubehörteile an, z. B. Maus, Tastatur, Bildschirm (nicht im Lieferumfang enthalten) und Ethernet.
- Schließen Sie das Netzkabel an die Buchse des Netzteils an.
- Verbinden Sie das DC-Kabel mit der DC-Buchse auf der Rückseite des Gerätes.
- Verbinden Sie das andere Ende des Netzkabels mit einer geeigneten Netzsteckdose.
- Schalten Sie das Gerät mit dem Tastsensor auf der Vorderseite ein.
IGEL UD3 M350C Technische Spezifikation
System
| Erhältliche Betriebssysteme | IGEL OS 11 |
| Management | IGEL Workspace Edition, Lizenzaktivierung nötig |
| Prozessor |
AMD Ryzen™ Embedded R1505G Dual-Core mit aktiviertem AMD Secure Prozessor und AMD Memory Guard |
Speicher
| RAM | 4 GB (2x 2GB SO-DIMM DDR4 2400 MHz) 2x32GB maximal |
|
Speicher |
8 GB (onboard eMMC) (verlötet) |
Grafik
| Chipsatz | AMD Radeon™ Vega 3 Graphics |
| Videospeicher | 512 MB Shared Memory |
| Anschlüsse |
2x DisplayPort 1.2 Multistream-Unterstützung: optional mit dem DP-MST-Adapter |
| Unterstützte Auflösungen |
2x 4K @60 Hz Unterstützt beschleunigte Videodekodierung für Auflösungen bis zu 2x 4K |
| Unterstützter Videokompressionsstandard |
H.264 |
Netzwerk
| Ethernet | 10/100/1000 Ethernet (RJ-45-Steckverbinder) |
| Drahtlos |
optional: |
Audio
| Chipsatz | Realtek ALC897 oder ALC888S HD Audio |
| Anschlüsse | 1x 3,5-mm-TRRS-Audiobuchse (CTIA-Standard) (Line-in / Line-out / Headset) |
| Lautsprecher |
1x intern |
Schnittstellen
| USB 3.2 Gen 1 oder Gen 2 (SuperSpeed USB) |
2x vorne |
| USB 3.2 Gen 1 Typ-C™ |
1x vorne Aufladen bis zu max. 7,5 W. Andere Alt-Modi (Alternate Modes) werden nicht unterstützt. |
| USB 2.0 |
2x hinten |
| DisplayPort 1.2 | 2x hinten |
| LAN | 1x hinten |
| Line-in / Line-out / Headset | 1x vorne |
| 12 V DC | 1x hinten |
| Diebstahlsicherung | 1x hinten |
| Smartcardleser | optional: 1x vorne (integrierter HID Omnikey 3121) |
| Seriell |
1x hinten (Chipsatz Prolific PL2303; inkl. 5 V-Spannungsversorgung) Hinweis: Die Reihenfolge der COM-Anschlüsse kann sich ändern, wenn ein USB-zu-Seriell-Adapter an UD3 M350C angeschlossen ist. |
Maße und Gewicht
| Gerät (TxBxH), stehend |
196 x 68 x 198 mm (mit Standfuß) |
| Gerätegewicht |
1,08 kg (mit Standfuß) |
| Verpackung (TxBxH), liegend |
225 x 275 x 95 mm |
| Verpackungsgewicht | 0,31 kg |
Betriebsumgebung
Beachten Sie unbedingt die Sicherheitshinweise und die Umgebungsbedingungen!
| Kühlung | lüfterlos |
| Betriebstemperatur |
vertikal (ohne VESA-Halterung): vertikal (mit VESA-Halterung): horizontal (nur mit optional erhältlichen Gummifüßen): |
| Luftfeuchtigkeit | 20 % – 80 %, nicht kondensierend |
Elektrische Daten
| Stromversorgung | extern |
| AC-Eingangsspannung | automatische Spannungsanpassung 100 – 240 V / 50 – 60 Hz |
| DC-Ausgangsspannung |
externes Netzteil 12 V / 4 A (48W) |
| Stromverbrauch |
5,45 W (idle) / 0,59 W (sleep) / < 0,48 W (aus) 5,32 W (idle) / 0,55 W (sleep) / < 0,48 W (aus) |
Typischer Energieverbrauch
(ENERGY STAR, 8.0)
| ETEC |
26,70 kWh (pro Jahr, @230 V) |
| ETEC, max | 33,0 kWh (pro Jahr, @230 / 115 V) |
Montagemöglichkeiten
| VESA-Halterung |
für Montage des Gerätes an der Monitorrückseite Wenn Sie zusätzlich eine Lösung für die Kabelmontage benötigen, siehe Mini-PC Cable-Caddy.* |
| Gummifüße | für horizontalen Betrieb |
Optional
| Integrierter Smartcardleser | für sichere Smartcard-basierte Authentifizierung |
| VESA-Halterung | für Montage an der Monitorrückseite |
| Gummifüße | für horizontalen Betrieb |
| USB-zu-Parallel-Adapter | zum Anschluss von Peripheriegeräten, die einen parallelen Port benötigen |
| USB-zu-Seriell-Adapter | zum Anschluss von Peripheriegeräten, die einen seriellen Port benötigen |
| Integriertes WLAN / Bluetooth | für drahtlose Konnektivität |
Umbauoptionen
HP T520
HP Desktop PCs – Informationen und Menüoptionen des BIOS Setup Utilitys
Hier erfahren Sie, wie Sie die allgemeinen BIOS-Menüs und -Einstellungen öffnen und dort navigieren. Bestimmte Menüs und Funktionen variieren je nach Computermodell.
Das BIOS (Basic Input/Output System) steuert die Kommunikation zwischen Systemgeräten wie Festplatte, Display und Tastatur. Es speichert auch Konfigurationsinformationen für Peripheriegerätetypen, die Startreihenfolge, die Größe des System- und des erweiterten Speichers und mehr. Jede BIOS-Version ist basierend auf der Hardwarekonfiguration der Computermodellreihe angepasst und enthält ein integriertes Setup Utility, das dazu dient, auf bestimmte Einstellungen des Computers zuzugreifen und diese zu ändern.
Wenn Sie das BIOS aktualisieren müssen, um ein spezifisches Problem zu beheben, die Leistung zu verbessern oder eine neue Hardwarekomponente oder ein Windows-Upgrade zu unterstützen, fahren Sie mit HP Consumer-Desktop PCs – Aktualisieren des BIOS (Basic Input/Output System) (Windows) fort. Sie können das BIOS unabhängig davon aktualisieren, ob Windows startet oder nicht startet.
Öffnen des BIOS-Einrichtungsdienstprogramms
Sie können das BIOS-Einrichtungsdienstprogramm während des Startvorgangs öffnen, indem Sie beim Systemstart eine Reihe von Tasten drücken.
-
Drücken Sie F10, um das BIOS-Einrichtungsdienstprogramm zu öffnen.

Festplatte:
Pi-hole Docker Howto
Solved: Error starting userland proxy: listen tcp4 0.0.0.0:53: bind: address already in use
Published by
Problem
While configuring the Duo Network Gateway (DNG) on a Ubuntu device for RDP, I came across the following error while trying to configure a DNS service:

The error is presented because the Ubuntu system is using the UDP port 53 (DNS). This is because there is a network name resolution service called systemd-resolved running by default. This service provides name resolution to local applications using the loopback IP of the device and acts by default as a DNS stub listener. It can also validate DNS/DNSSEC and can be configured for Link-Local Multicast Name Resolution (LLMNR) which when enabled will become a full LLMNR responder and resolver. There are a few other things that systemd-resolved can do but for this article, we won’t discuss those as they’re not relevant. You can find out more about systemd-resolved here.
Solution
II’ve seen articles on the Internet recommending that systemd-resolved should be disabled if you encounter this issue. However, by disabling systemd-resolved, the name resolution will not work, so we need to take another approach. The approach that we’re going to take in this article is to modify the resolved.conf for systemd-resolved. We will modify the configuration so that it no longer listens for DNS requests but rather uses the configured DNS servers for that task.
Verify that port 53 is used on your DNG
Although you have experienced the aforementioned error that more than likely brought you here, let’s not jump the gun! We want to start by checking what is using port 53. Enter the following command to valid port 53 is indeed in use.
sudo lsof -i udp:53You should recieve a similar output to the one shown in the screenshot below. Here we confirm that systemd-resolved is indeed using UDP 53 (DNS).

We can further validate this by performing an NSLOOKUP to see what the system uses to resolve FQDN’s. Enter the following command.
sudo nslookup google.comThe results should be similar to the screenshot below. You can see that the DNG is using itself to cache and perform DNS lookups.

If you are using an Ubuntu or Fedora operating system to run the Pi-Hole Docker container, you may need to disable the DNS Stub listener that is built into the Systemd resolve service.
The operating system uses this service to provide network name resolution. As Pi-Hole will want to operate on the same part the resolve service does, we need to disable it.
To start this process, begin editing the “/etc/systemd/resolved.conf” configuration file by running the following command.
sudo nano /etc/systemd/resolved.confCopy8. Within this file, you will want to find the following line. This setting basically allows us to control whether the DNS stub listener is turned on.
#DNSStubListener=yesCopyAfter finding this line you will want to remove the hashtag (#) from the front of this line and change “yes” to “no“.
DNSStubListener=noCopy9. Once you have made this change, save and quit out of the file by pressing CTRL + X, Y, and then ENTER.
10. Our next step is to remove the existing “resolv.conf” file since it currently points your system’s network to use the now-disabled DNS stub resolver.
You can delete this file using the rm command as shown below.
sudo rm /etc/resolv.confCopy11. With the existing “resolv.conf” file removed, we will now create a symbolic link in its place pointing to the version setting in the “/run/systemd/resolve/” directory.
This version of the file is automatically updated using the DNS servers set within your Netplan.
sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.confCopy12. The last thing we need to do is restart the “systemd-resolved” service so that all of our changes will be loaded in.
Once the service has finished restarting, Pi-hole should now be able to utilize the DNS ports on your system.
sudo systemctl restart systemd-resolvedsudo systemctl stop systemd-resolved
nslookup google.comComposefile:
IGEL 350c - SATA / NVME
Einbau einer Festplatte
Man kann das WLAN-/BT - Modul ausbauen und mit entsprechenden Adapterkarten den Mini-PCIE-Slot zum Anschluss einer Festplatte verwenden. So lässt sich entweder eine NVME oder SATA Festplatte verbauen. Beim Einbau einer SATA-Festplatte wird, um Platz zu sparen, das nackte Modul verbaut und an einen der freien Pfosten angeschraubt, die für den Kartenleser gedacht sind, der in unseren Geräten allerdings nicht eingebaut ist.
Teile für SATA:


Teile für NVME:
Formfaktor 2230, 2240

Geschwindigkeitstest SATA 3.0:
/dev/sda:
Timing O_DIRECT cached reads: 958 MB in 2.00 seconds = 478.59 MB/sec
Timing O_DIRECT disk reads: 1504 MB in 3.00 seconds = 500.72 MB/sec
Test Schreibgeschwindigkeit 1000 Blöcke a 1MB
1024+0 Datensätze ein
1024+0 Datensätze aus
1073741824 Byte (1,1 GB, 1,0 GiB) kopiert, 2,67673 s, 401 MB/s
2.Test Lesegeschwindigkeit 1000 Blöcke a 1MB
1024+0 Datensätze ein
1024+0 Datensätze aus
1073741824 Byte (1,1 GB, 1,0 GiB) kopiert, 1,95155 s, 550 MB/s
Geschwindigkeitstest NVME:
Test Schreibgeschwindigkeit 1000 Blöcke a 1MB
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 1.49458 s, 718 MB/s
2.Test Lesegeschwindigkeit 1000 Blöcke a 1MB
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 1.32354 s, 811 MB/s
Alternativ:

Openmediavault (NAS), auf einem IGEL 340C
Hardware: IGEL M340C :

Die Hardware ist sparsam, lautlos im Betrieb, standfest und eignet sich daher durchaus für den Dauerbetrieb.
Ohne großen Aufwand lässt sich aus den IGEL-Geräten ein ganz ordentliches NAS-System bauen. Die Basis ist die auf Debian-Linux basierende NAS-Software "Openmediavault". Die ist modular aufgebaut und vielseitig erweiterbar, je nachdem, was man damit machen möchte, belässt man es bei der Basisinstallation oder installiert einige der zahlreichen Erweiterungen, die verfügbar sind.
Für einen einfachen File-Server reicht die Basisinstallation schon aus und auch die 2 GB RAM, die im Default verbaut sind. Benötigt wird lediglich eine größere Festplatte ->s.u. .
Mit mehr RAM ( maximal 8Gb DDR3-SO-Dimm gehen in den einzigen Steckplatz) und einigen Erweiterungen .z.B. Docker ergeben sich sehr viele Möglichkeiten, Anwendungen oder Dienste auf dem Gerät laufen zu lassen. Die verbaute CPU mit vier Kernen bietet für die meisten Anwendungen genug Leistung an, um einen flüssigen Betrieb zu ermöglichen.
Demo
IGEL-NAS (Beispiel mit einigen installierten Containern und Portalseite).
Hint: Die Logins zu den einzelnen Anwendungen stehen im Mouseover-Text.
Nach der Anmeldung unter "Openmediavault" richtet man als erstes das Dashbord ein (oben rechts unter dem Usersymbol) und hat einen Überblick darüber, was so vor sich geht.
NAS: ->Handbuch
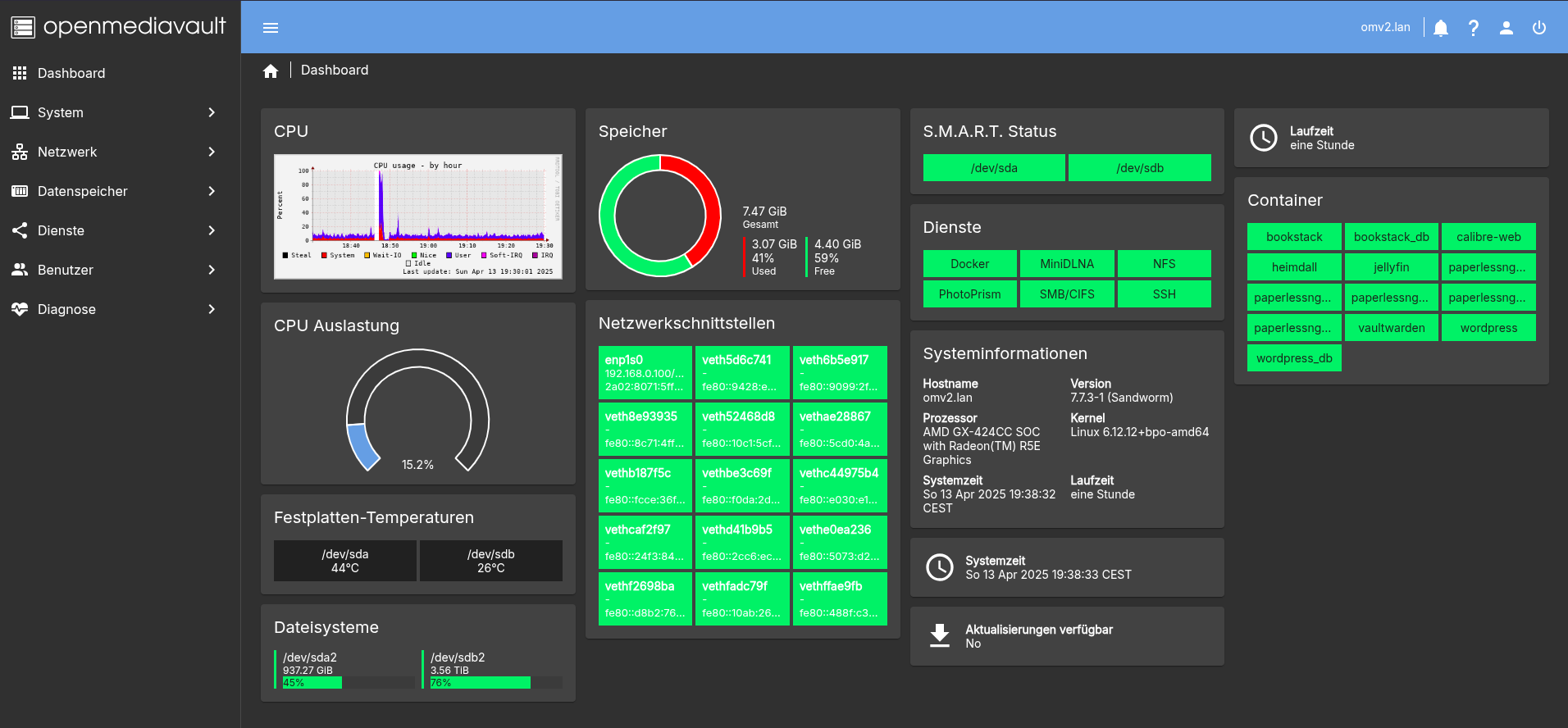
Zahlreiche Plugins zu Multimedia, Containerverwaltung wie Kubernetes oder Podman oder auch zur Verwaltung von Photos.
z.B : Photoprism (Bilderverwaltung)
Festplatte:
- Umrüstung: Adapterkarte SATA auf mSATA , mSATA MO-300
- Alternativ kann man auch eine 2,5" - SSD auseinander nehmen, da die meisten darin verwendeten Module exakt so aufgebaut sind gebaut sind wie die abgebildete Adapterkarte.

- Der IGEL-M430C verwendet DDR3 SO-Dimm Speicher, verfügt über einen Slot, der mit maximal 8 GB bestückt werden kann.
- Es sind 2 USB3-Anschlüsse vorhanden, an denen z.B. externe Festplatten angeschlossen werden können.
Openmediavault
- Defaultanmeldung beim NAS: user: admin pass: openmediavault
_____________________________________________________________________
In der Basisversion der Installation ist alles vorhanden, was nötig ist, um ein einfaches NAS als Datengrab damit zu betreiben. Die Software enthält per Default diverse Plugins und Erweiterungen (z.B. Photoprism), mit dem sich weitere Funktionen installieren lassen.
Darüberhinaus gibt es wie gesagt noch zahllose Erweiterungen wie Docker z.B., womit Container installiert und verwaltet werden können. Für den Einsteiger gibt's dazu zahlreiche Templates, die einfach angepasste werden können. Diese Erweiterungen sind in den OMV-Extra Repository enthalten und werden auf der Kommandozeile mit:
wget -O - https://github.com/OpenMediaVault-Plugin-Developers/packages/raw/master/install | bash
installiert.